Posts tagged "haskell":
Validation of data in a servant server
I've been playing around with adding more validation of data received by an HTTP
endpoint in a servant server. Defining a type with a FromJSON instance is very
easy, just derive a Generic instance and it just works. Here's a simple
example
data Person = Person
{ name :: Text
, age :: Int
, occupation :: Occupation
}
deriving (Generic, Show)
deriving (FromJSON, ToJSON) via (Generically Person)
data Occupation = UnderAge | Student | Unemployed | SelfEmployed | Retired | Occupation Text
deriving (Eq, Generic, Ord, Show)
deriving (FromJSON, ToJSON) via (Generically Occupation)
However, the validation is rather limited, basically it's just checking that
each field is present and of the correct type. For the type above I'd like to
enforce some constraints for the combination of age and occupation.
The steps I thought of are
- Hide the default constructor and define a smart one. (This is the standard suggestion for placing extra constraints values.)
- Manually define the
FromJSONinstance using theGenericinstance to limit the amount of code and the smart constructor.
The smart constructor
I give the constructor the result type Either String Person to make sure it
can both be usable in code and when defining parseJSON.
mkPerson :: Text -> Int -> Occupation -> Either String Person
mkPerson name age occupation = do
guardE mustBeUnderAge
guardE notUnderAge
guardE tooOldToBeStudent
guardE mustBeRetired
pure $ Person name age occupation
where
guardE (pred, err) = when pred $ Left err
mustBeUnderAge = (age < 8 && occupation > UnderAge, "too young for occupation")
notUnderAge = (age > 15 && occupation == UnderAge, "too old to be under age")
tooOldToBeStudent = (age > 45 && occupation == Student, "too old to be a student")
mustBeRetired = (age > 65 && occupation /= Retired, "too old to not be retired")
Here I'm making use of Either e being a Monad and use when to apply the
constraints and ensure the reason for failure is given to the caller.
The FromJSON instance
When defining the instance I take advantage of the Generic instance to make
the implementation short and simple.
instance FromJSON Person where
parseJSON v = do
Person{name, age, occupation} <- genericParseJSON defaultOptions v
either fail pure $ mkPerson name age occupation
If there are many more fields in the type I'd consider using RecordWildCards.
Conclusion
No, it's nothing ground-breaking but I think it's a fairly nice example of how things can fit together in Haskell.
Reading Redis responses
When I began experimenting with writing a new Redis client package I decided to use lazy bytestrings, because:
- aeson seems to prefer it – the main encoding and decoding functions use lazy byte strings, though there are strict variants too.
- the
Buildertype in bytestring produce lazy bytestrings.
At the time I was happy to see that attoparsec seemed to support strict and lazy bytestrings equally well.
To get on with things I also wrote the simplest function I could come up with
for sending and receiving data over the network – I used send and recv from
Network.Socket.ByteString.Lazy in network. The function was really simple
import Network.Socket.ByteString.Lazy qualified as SB
sendCmd :: Conn -> Command r -> IO (Result r)
sendCmd (Conn p) (Command k cmd) = withResource p $ \sock -> do
_ <- SB.send sock $ toWireCmd cmd
resp <- SB.recv sock 4096
case decode resp of
Left err -> pure $ Left $ RespError "decode" (TL.pack err)
Right r -> pure $ k <$> fromWireResp cmd r
with decode defined like this
decode :: ByteString -> Either String Resp
decode = parseOnly resp
I knew I'd have to revisit this function, it was naïve to believe that a call to
recv would always result in as single complete response. It was however good
enough to get going. When I got to improving sendCmd I was a little surprised
to find that I'd also have to switch to using strict bytestrings in the parser.
Interlude on the Redis serialisation protocol (RESP3)
The Redis protocol has some defining attributes
- It's somewhat of a binary protocol. If you stick to keys and values that fall
within the set of ASCII strings, then the protocol is humanly readable and you
can rather easily use
netcatortelnetas a client. However, you aren't limited to storing only readable strings. - It's somewhat of a request-response protocol. A notable exception is the publish-subscribe subset, but it's rather small and I reckon most Redis users don't use it.
- It's somewhat of a type-length-value style protocol. Some of the data types include their length in bytes, e.g. bulk strings and verbatim strings. Other types include the number of elements, e.g. arrays and maps. A large number of them have no length at all, e.g. simple strings, integers, and doubles.
I suspect there are good reasons, I gather a lot of it has to do with speed. It does however cause one issue when writing a client: it's not possible to read a whole response without parsing it.
Rewriting sendCmd
With that extra information about the RESP3 protocol the naïve implementation above falls short in a few ways
- The read buffer may contain more than one full message and give the definition
of
decodeabove any remaining bytes are simply dropped.1 - The read buffer my contain less than one full message and then
decodewill return an error.2
Surely this must be solvable, because in my mind running the parser results in one of three things:
- Parsing is done and the result is returned, together with any input that wasn't consumed.
- The parsing is not done due to lack of input, this is typically encoded as a continuation.
- The parsing failed so the error is returned, together with input that wasn't consumed.
So, I started looking in the documentation for the module
Data.Attoparsec.ByteString.Lazy in attoparsec. I was a little surprised to find
that the Result type lacked a way to feed more input to a parser – it only
has two constructors, Done and Fail:
data Result r
= Fail ByteString [String] String
| Done ByteString r
I'm guessing the idea is that the function producing the lazy bytestring in the
first place should be able to produce more chunks of data on demand. That's
likely what the lazy variant of recv does, but at the same time it also
requires choosing a maximum length and that doesn't rhyme with RESP3. The lazy
recv isn't quite lazy in the way I needed it to be.
When looking at the parser for strict bytestrings I calmed down. This parser
follows what I've learned about parsers (it's not defined exactly like this;
it's parameterised in its input but for the sake of simplicity I show it with
ByteString as input):
data Result r
= Fail ByteString [String] String
| Partial (ByteString -> Result r)
| Done ByteString r
Then to my delight I found that there's already a function for handling exactly my problem
parseWith :: Monad m => (m ByteString) -> Parser a -> ByteString -> m (Result a)
I only needed to rewrite the existing parser to work with strict bytestrings and
work out how to write a function using recv (for strict bytestrings) that
fulfils the requirements to be used as the first argument to parseWith. The
first part wasn't very difficult due to the similarity between attoparsec's
APIs for lazy and strict bytestrings. The second only had one complication. It
turns out recv is blocking, but of course that doesn't work well with
parseWith. I wrapped it in timeout based on the idea that timing out means
there's no more data and the parser should be given an empty string so it
finishes. I also decided to pass the parser as an argument, so I could use the
same function for receiving responses for individual commands as well as for
pipelines. The full receiving function is
import Data.ByteString qualified as BS
import Data.Text qualified as T
import Network.Socket.ByteString qualified as SB
recvParse :: S.Socket -> Parser r -> IO (Either Text (BS.ByteString, r))
recvParse sock parser = do
parseWith receive parser BS.empty >>= \case
Fail _ [] err -> pure $ Left (T.pack err)
Fail _ ctxs err -> pure $ Left $ T.intercalate " > " (T.pack <$> ctxs) <> ": " <> T.pack err
Partial _ -> pure $ Left "impossible error"
Done rem result -> pure $ Right (rem, result)
where
receive =
timeout 100_000 (SB.recv sock 4096) >>= \case
Nothing -> pure BS.empty
Just bs -> pure bs
Then I only needed to rewrite sendCmd and I wanted to do it in such a way that
any remaining input data could be use in by the next call to sendCmd.3 I
settled for modifying the Conn type to hold an IORef ByteString together
with the socket and then the function ended up looking like this
sendCmd :: Conn -> Command r -> IO (Result r)
sendCmd (Conn p) (Command k cmd) = withResource p $ \(sock, remRef) -> do
_ <- SBL.send sock $ toWireCmd cmd
rem <- readIORef remRef
recvParse sock rem resp >>= \case
Left err -> pure $ Left $ RespError "recv/parse" err
Right (newRem, r) -> do
writeIORef remRef newRem
pure $ k <$> fromWireResp cmd r
What's next?
I've started looking into pub/sub, and basically all of the work described in this post is a prerequisite for that. It's not very difficult on the protocol level, but I think it's difficult to come up with a design that allows maximal flexibility. I'm not even sure it's worthwhile the complexity.
Footnotes:
This isn't that much of a problem when sticking to the request-response commands, I think. It most certainly becomes a problem with pub/sub though.
I'm sure that whatever size of buffer I choose to use there'll be someone out there who's storing values that are larger. Then there's pipelining that makes it even more of an issue.
To be honest I'm not totally convinced there'll ever be any remaining input.
Unless a single Conn is used by several threads – which would lead to much
pain with the current implementation – or pub/sub is used – which isn't
supported yet.
Finding a type for Redis commands
Arriving at a type for Redis commands required a bit of exploration. I had some ideas early on that I for various reasons ended up dropping on the way. This is a post about my travels, hopefully someone finds it worthwhile reading.
The protocol
The Redis Serialization Protocol (RESP) initially reminded me of JSON and I
thought that following the pattern of aeson might be a good idea. I decided
up-front that I'd only support the latest version of RESP, i.e. version 3. So, I
thought of a data type, Resp with a constructor for each RESP3 data type, and
a pair of type classes, FromResp and ToResp for converting between Haskell
types and RESP3. Then after some more reflection I realised that converting to
RESP is largely pointless. The main reason to convert anything to RESP3 is to
assemble a command, with its arguments, to send to Redis, but all commands are
arrays of bulk strings so it's unlikely that anyone will actually use
ToResp.1 So I scrapped the idea of ToResp. FromResp looked like this
class FromResp a where fromResp :: Value -> Either FromRespError a
When I started defining commands I didn't like the number of ByteString
arguments that resulted in, so I defined a data type, Arg, and an accompanying
type class for arguments, ToArg:
newtype Arg = Arg {unArg :: [ByteString]} deriving (Show, Semigroup, Monoid) class ToArg a where toArg :: a -> Arg
Later on I saw that it might also be nice to have a type class specifically for
keys, ToKey, though that's a wrapper for a single ByteString.
Implementing the functions to encode/decode the protocol were straight-forward
applications of attoparsec and bytestring (using its Builder).
A command is a function in need of a sender
Even though supporting pipelining was one of the goals I felt a need to make sure I'd understood the protocol so I started off with single commands. The protocol is a simple request/response protocol at the core so I settled on this type for commands
type Cmd a = forall m. (Monad m) => (ByteString -> m ByteString) -> m (Either FromRespError a)
that is, a command is a function accepting a sender and returning an a.
I wrote a helper function for defining commands, sendCmd
sendCmd :: (Monad m, FromResp a) => [ByteString] -> (ByteString -> m ByteString) -> m (Either FromRespError a) sendCmd cmdArgs send = do let cmd = encode $ Array $ map BulkString cmdArgs send cmd <&> decode >>= \case Left desc -> pure $ Left $ FromRespError "Decode" (Text.pack desc) Right v -> pure $ fromValue v
which made it easy to define commands. Here are two examples, append and mget:
append :: (ToArg a, ToArg b) => a -> b -> Cmd Int append key val = sendCmd $ ["APPEND"] <> unArg (toArg key <> toArg val) -- | https://redis.io/docs/latest/commands/mget/ mget :: (ToArg a, FromResp b) => NE.NonEmpty a -> Cmd (NE.NonEmpty b) mget ks = sendCmd $ ["MGET"] <> unArg (foldMap1 toArg ks)
The function to send off a command and receive its response, sendAndRecieve,
was just a call to send followed by a call to recv in network (the variants
for lazy bytestrings).
I sort of liked this representation – there's always something pleasant with finding a way to represent something as a function. There's a very big problem with it though: it's difficult to implement pipelining!
Yes, Cmd is a functor since (->) r is a functor, and thus it's possible to
make it an Applicative, e.g. using free. However, to implement pipelining it's
necessary to
- encode all commands, then
- concatenate them all into a single bytestring and send it
- read the response, which is a concatenation of the individual commands' responses, and
- convert each separate response from RESP3.
That isn't easy when each command contains its own encoding and decoding. The sender function would have to relinquish control after encoding the command, and resume with the resume again later to decode it. I suspect it's doable using continuations, or monad-coroutine, but it felt complicated and rather than travelling down that road I asked for ideas on the Haskell Discourse. The replies lead me to a paper, Free delivery, and a bit later a package, monad-batcher. When I got the pointer to the package I'd already read the paper and started implementing the ideas in it, so I decided to save exploring monad-batcher for later.
A command for free delivery
The paper Free delivery is a perfect match for pipelining in Redis, and my understanding is that it proposes a solution where
- Commands are defined as a GADT,
Command a. - Two functions are defined to serialise and deserialise a
Command a. In the paper they useStringas the serialisation, soshowandreadis used. - A type,
ActionA a, is defined that combines a command with a modification of itsaresult. It implementsFunctor. - A free type,
FreeA f ais defined, and made into anApplicativewith the constraint thatfis aFunctor. - A function,
serializeA, is defined that traverses aFreeA ActionA aserialising each command. - A function,
deserializeA, is defined that traverses aFreeA ActionA adeserialising the response for each command.
I defined a command type, Command a, with only three commands in it, echo,
hello, and ping. I then followed the recipe above to verify that I could get
it working at all. The Haskell used in the paper is showing its age, and there
seems to be a Functor instance missing, but it was still straight forward and
I could verify that it worked against a locally running Redis.
Then I made a few changes…
I renamed the command type to Cmd so I could use Command for what the
paper calls ActionA.
data Cmd r where Echo :: Text -> Cmd Text Hello :: Maybe Int -> Cmd () Ping :: Maybe Text -> Cmd Text data Command a = forall r. Command !(r -> a) !(Cmd r) instance Functor Command where fmap f (Command k c) = Command (f . k) c toWireCmd :: Cmd r -> ByteString toWireCmd (Echo msg) = _ toWireCmd (Hello ver) = _ toWireCmd (Ping msg) = _ fromWireResp :: Cmd r -> Resp -> Either RespError r fromWireResp (Echo _) = fromResp fromWireResp (Hello _) = fromResp fromWireResp (Ping _) = fromResp
(At this point I was still using FromResp.)
I also replaced the free applicative defined in the paper and started using free. A couple of type aliases make it a little easier to write nice signatures
type Pipeline a = Ap Command a type PipelineResult a = Validation [RespError] a
and defining individual pipeline commands turned into something rather
mechanical. (I also swapped the order of the arguments to build a Command so I
can use point-free style here.)
liftPipe :: (FromResp r) => Cmd r -> Pipeline r liftPipe = liftAp . Command id echo :: Text -> Pipeline Text echo = liftPipe . Echo hello :: Maybe Int -> Pipeline () hello = liftPipe . Hello ping :: Maybe Text -> Pipeline Text ping = liftPipe . Ping
One nice thing with switching to free was that serialisation became very simple
toWirePipeline :: Pipeline a -> ByteString toWirePipeline = runAp_ $ \(Command _ c) -> toWireCmd c
On the other hand deserialisation became a little more involved, but it's not too bad
fromWirePipelineResp :: Pipeline a -> [Resp] -> PipelineResult a fromWirePipelineResp (Pure a) _ = pure a fromWirePipelineResp (Ap (Command k c) p) (r : rs) = fromWirePipelineResp p rs <*> (k <$> liftError singleton (fromWireResp c r)) fromWirePipelineResp _ _ = Failure [RespError "fromWirePipelineResp" "Unexpected wire result"]
Everything was working nicely and I started adding support for more commands. I used the small service from work to guide my choice of what commands to add. First out was del, then get and set. After adding lpush I was pretty much ready to try to replace hedis in the service from work.
data Cmd r where -- echo, hello, ping Del :: (ToKey k) => NonEmpty k -> Cmd Int Get :: (ToKey k, FromResp r) => k -> Cmd r Set :: (ToKey k, ToArg v) => k -> v -> Cmd Bool Lpush :: (ToKey k, ToArg v) => k -> NonEmpty v -> Cmd Int
However, when looking at the above definition started I thinking.
- Was it really a good idea to litter
Cmdwith constraints like that? - Would it make sense to keep the
Cmdtype a bit closer to the actual Redis commands? - Also, maybe
FromRespwasn't such a good idea after all, what if I remove it?
That brought me to the third version of the type for Redis commands.
Converging and simplifying
While adding new commands and writing instances of FromResp I slowly realised
that my initial thinking of RESP3 as somewhat similar to JSON didn't really pan
out. I had quickly dropped ToResp and now the instances of FromResp didn't
sit right with me. They obviously had to "follow the commands", so to speak, but
at the same time allow users to bring their own types. For instance, LSPUSH
returns the number of pushed messages, but at the same time GET should be able
to return an Int too. This led to Int's FromResp looking like this
instance FromResp Int where fromResp (BulkString bs) = case parseOnly (AC8.signed AC8.decimal) bs of Left s -> Left $ RespError "FromResp" (TL.pack s) Right n -> Right n fromResp (Number n) = Right $ fromEnum n fromResp _ = Left $ RespError "FromResp" "Unexpected value"
I could see this becoming worse, take the instance for Bool, I'd have to
consider that
- for
MOVEInteger 1meansTrueandInteger 0meansFalse - for
SETSimpleString "OK"meansTrue - users would justifiably expect a bunch of bytestrings to be
True, e.g.BulkString "true",BulkString "TRUE",BulkString "1", etc
However, it's impossible to cover all ways users can encode a Bool in a
ByteString so no matter what I do users will end up having to wrap their
Bool with newtype and implement a fitting FromResp. On top of that, even
thought I haven't found any example of it yet, I fully expect there to be,
somewhere in the large set of Redis commands, at least two commands each wanting
an instance of a basic type that simply can't be combined into a single
instance, meaning that the client library would need to do some newtype
wrapping too.
No, I really didn't like it! So, could I get rid of FromResp and still offer
users an API where they can user their own types as the result of commands?
To be concrete I wanted this
data Cmd r where -- other commands Get :: (ToKey k) => k -> Cmd (Maybe ByteString)
and I wanted the user to be able to conveniently turn a Cmd r into a Cmd s.
In other words, I wanted a Functor instance. Making Cmd itself a functor
isn't necessary and I just happened to already have a functor type that wraps
Cmd, the Command type I used for pipelining. If I were to use that I'd need
to write wrapper functions for each command though, but if I did that then I
could also remove the ToKey~/~ToArg constraints from the constructors of Cmd
r and put them on the wrapper instead. I'd get
data Cmd r where -- other commands Get :: Key -> Cmd (Maybe ByteString) get :: (ToKey k) => k -> Command (Maybe ByteString) get = Command id . Get . toKey
I'd also have to rewrite fromWireResp so it's more specific for each command.
Instead of
fromWireResp :: Cmd r -> Resp -> Either RespError r fromWireResp (Get _) = fromResp ...
I had to match up exactly on the possible replies to GET
fromWireResp :: Cmd r -> Resp -> Either RespError r fromWireResp _ (SimpleError err desc) = Left $ RespError (T.decodeUtf8 err) (T.decodeUtf8 desc) fromWireResp (Get _) (BulkString bs) = Right $ Just bs fromWireResp (Get _) Null = Right Nothing ... fromWireResp _ _ = Left $ RespError "fromWireResp" "Unexpected value"
Even though it was more code I liked it better than before, and I think it's slightly simpler code. I also hope it makes the use of the API is a bit simpler and clear.
Here's an example from the code for the service I wrote for work. It reads a UTC
timestamp stored in timeKey, the timestamp is a JSON string so it needs to be
decoded.
readUTCTime :: Connection -> IO (Maybe UTCTime) readUTCTime conn = sendCmd conn (maybe Nothing decode <$> get timeKey) >>= \case Left _ -> pure Nothing Right datum -> pure datum
What's next?
I'm pretty happy with the command type for now, though I have a feeling I'll
have to revisit Arg and ToArg at some point.
I've just turned the Connection type into a pool using resource-pool, and I
started looking at pub/sub. The latter thing, pub/sub, will require some thought
and experimentation I think. Quite possibly it'll end up in a post here too.
I also have a lot of commands to add.
Footnotes:
Of course one could use RESP3 as the serialisation format for storing values in Redis. Personally I think I'd prefer using something more widely used, and easier to read, such as JSON or BSON.
Why I'm writing a Redis client package
A couple of weeks ago I needed a small, hopefully temporary, service at work. It bridges a gap in functionality provided by a legacy system and the functionality desired by a new system. The legacy system is cumbersome to work with, so we tend to prefer building anti-corruption layers rather than changing it directly, and sometimes we implement it as separate services.
This time it was good enough to run the service as a cronjob, but it did need to keep track of when it ran the last time. It felt silly to spin up a separate DB just to keep a timestamp, and using another service's DB is something I really dislike and avoid.1 So, I ended up using the Redis instance that's used as a cache by a OSS service we host.
The last time I had a look at the options for writing a Redis client in Haskell I found two candidates, hedis and redis-io. At the time I wrote a short note about them. This time around I found nothing much has changed, they are still the only two contenders and they still suffer from the same issues
- hedis has still has the same API and I still find it as awkward.
- redis-io still requires a logger.
I once again decided to use hedis and wrote the service for work in a couple of days, but this time I thought I'd see what it would take to remove the requirement on tinylog from redis-io. I spent a few evenings on it, though I spent most time on "modernising" the dev setup, using Nix to build, re-format using fourmolu, etc. I did the same for redis-resp, the main dependency of redis-io. The result of that can be found on my gitlab account:
At the moment I won't take that particular experiment any further and given that the most recent change to redis-io was in 2020 (according to its git repo) I don't think there's much interest upstream either.
Making the changes to redis-io and redis-resp made me a little curious about the Redis protocol so I started reading about it. It made me start thinking about implementing a client lib myself. How hard could it be?
I'd also asked a question about Redis client libs on r/haskell and a response
led me to redis-schema. It has a very good README, and its section on
transactions with its observation that Redis transactions are a perfect match
for Applicative. This pushed me even closer to start writing a client lib.
What pushed me over the edge was the realisation that pipelining also is a
perfect match for Applicative.
For the last few weeks I've spent some of my free time reading and experimenting and I'm enjoying it very much. We'll see where it leads, but hopefully I'll at least have bit more to write about it.
Footnotes:
One definition of a microservice I find very useful is "a service that owns its own DB schema."
Using lens-aeson to implement FromJSON
At work I sometimes need to deal with large and deep JSON objects where I'm only
interested in a few of the values. If all the interesting values are on the top
level, then aeson have functions that make it easy to implement FromJSON's
parseJSON (Constructors and accessors), but if the values are spread out then
the functions in aeson come up a bit short. That's when I reach for lens-aeson,
as lenses make it very easy to work with large structures. However, I've found
that using its lenses to implement parseJSON become a lot easier with a few
helper functions.
Many of the lenses produces results wrapped in Maybe, so the first function is
one that transforms a Maybe a to a Parser a. Here I make use of Parser
implementing MonadFail.
infixl 8 <!> (<!>) :: (MonadFail m) => Maybe a -> String -> m a (<!>) mv err = maybe (fail err) pure mv
In some code I wrote this week I used it to extract the user name out of a JWT produced by Keycloak:
instance FromJSON OurClaimsSet where parseJSON = ... $ \o -> do cs <- parseJSON o n <- o ^? key "preferred_username" . _String <!> "preferred username missing" ... pure $ OurClaimsSet cs n ...
Also, all the lenses start with a Value and that makes the withX functions
in aeson to not be a perfect fit. So I define variations of the withX
functions, e.g.
withObjectV :: String -> (Value -> Parser a) -> Value -> Parser a withObjectV s f = withObject s (f . Object)
That makes the full FromJSON instance for OurClaimsSet look like this
instance FromJSON OurClaimsSet where parseJSON = withObjectV "OurClaimsSet" $ \o -> do cs <- parseJSON o n <- o ^? key "preferred_username" . _String <!> "name" let rs = o ^.. key "resource_access" . members . key "roles" . _Array . traverse . _String pure $ OurClaimsSet cs n rs
Servant and a weirdness in Keycloak
When writing a small tool to interface with Keycloak I found an endpoint that
require the content type to be application/json while the body should be plain
text. (The details are in the issue.) Since servant assumes that the content
type and the content match (I know, I'd always thought that was a safe
assumption to make too) it doesn't work with ReqBody '[JSON] Text. Instead I
had to create a custom type that's a combination of JSON and PlainText,
something that turned out to required surprisingly little code:
data KeycloakJSON deriving (Typeable) instance Accept KeycloakJSON where contentType _ = "application" // "json" instance MimeRender KeycloakJSON Text where mimeRender _ = fromStrict . encodeUtf8
The bug has already been fixed in Keycloak, but I'm sure there are other APIs with similar weirdness so maybe this will be useful to someone else.
Hoogle setup for local development
About a week ago I asked a question on the Nix Discourse about how to create a setup for Hoogle that
- includes the locally installed packages, and
- the package I'm working on, and ideally also
- have all local links, i.e. no links to Hackage.
I didn't get an answer there, but some people on the Nix Haskell channel on Matrix helped a bit, but it seems this particular use case requires a bit of manual work. The following commands get me an almost fully working setup:
cabal haddock --haddock-internal --haddock-quickjump --haddock-hoogle --haddock-html hoogle_dir=$(dirname $(dirname $(readlink -f $(which hoogle)))) hoogle generate --database=local.hoo \ $(for d in $(fd -L .txt ${hoogle_dir}); do printf "--local=%s " $(dirname $d); done) \ --local=./dist-newstyle/build/x86_64-linux/ghc-9.8.2/pkg-0.0.1/doc/html/pkg hoogle server --local --database=local.foo
What's missing is working links between the documentation of locally installed
packages. It looks like the links in the generated documention in Nix have a lot
of relative references containing ${pkgroot}/../../../../ which is what I
supect causes the broken links.
Nix, cabal, and tests
At work I decided to attempt to change the setup of one of our projects from using
to the triplet I tend to prefer
During this I ran into two small issues relating to tests.
hspec-discover both is, and isn't, available in the shell
I found mentions of this mentioned in an open cabal ticket and someone even made a git repo to explore it. I posted a question on the Nix discorse.
Basically, when running cabal test in a dev shell, started with nix develop,
the tool hspec-discover wasn't found. At the same time the packages was
installed
(ins)$ ghc-pkg list | rg hspec hspec-2.9.7 hspec-core-2.9.7 (hspec-discover-2.9.7) hspec-expectations-0.8.2
and it was on the $PATH
(ins)$ whereis hspec-discover hspec-discover: /nix/store/vaq3gvak92whk5l169r06xrbkx6c0lqp-ghc-9.2.8-with-packages/bin/hspec-discover /nix/store/986bnyyhmi042kg4v6d918hli32lh9dw-hspec-discover-2.9.7/bin/hspec-discover
The solution, as the user julm pointed out, is to simply do what cabal tells
you and run cabal update first.
Dealing with tests that won't run during build
The project's tests were set up in such a way that standalone tests and
integration tests are mixed into the same test executable. As the integration
tests need the just built service to be running they can't be run during nix
build. However, the only way of preventing that, without making code changes,
is to pass an argument to the test executable, --skip=<prefix>, and I believe
that's not possible when using developPackage. It's not a big deal though,
it's perfectly fine to run the tests separately using nix develop . command
.... However, it turns out developPackage and the underlying machinery is
smart enough to skip installing package required for testing when it's turned
off (using dontCheck). This is the case also when returnShellEnv is true.
Luckily it's not too difficult to deal with it. I already had a variable
isDevShell so I could simply reuse it and add the following expression to
modifier
(if isDevShell then hl.doCheck else hl.dontCheck)
Update to Hackage revisions in Nix
A few days after I published Hackage revisions in Nix I got a comment from
Wolfgang W that the next release of Nix will have a callHackageDirect with
support for specifying revisions.
The code in PR #284490 makes callHackageDirect accept a rev argument. Like
this:
haskellPackages.callHackageDirect { pkg = "openapi3"; ver = "3.2.3"; sha256 = "sha256-0F16o3oqOB5ri6KBdPFEFHB4dv1z+Pw6E5f1rwkqwi8="; rev = { revision = "4"; sha256 = "sha256-a5C58iYrL7eAEHCzinICiJpbNTGwiOFFAYik28et7fI="; }; } { }
That's a lot better than using overrideCabal!
Hackage revisions in Nix
Today I got very confused when using callHackageDirect to add the openapi3
package gave me errors like this
> Using Parsec parser > Configuring openapi3-3.2.3... > CallStack (from HasCallStack): > withMetadata, called at libraries/Cabal/Cabal/src/Distribution/Simple/Ut... > Error: Setup: Encountered missing or private dependencies: > base >=4.11.1.0 && <4.18, > base-compat-batteries >=0.11.1 && <0.13, > template-haskell >=2.13.0.0 && <2.20
When looking at its entry on Hackage those weren't the version ranges for the
dependencies. Also, running ghc-pkg list told me that I already had all
required packages at versions matching what Hackage said. So, what's actually
happening here?
It took me a while before remembering about revisions but once I did it was
clear that callHackageDirect always fetches the initial revision of a package
(i.e. it fetches the original tar-ball uploaded by the author). After realising
this it makes perfect sense – it's the only revision that's guaranteed to be
there and won't change. However, it would be very useful to be able to pick a
revision that actually builds.
I'm not the first one to find this, of course. It's been noted and written about
on the discource several years ago. What I didn't find though was a way to
influence what revision that's picked. It took a bit of rummaging around in the
nixpkgs code but finally I found two variables that's used in the Hackage
derivation to control this
revision- a string with the number of the revision, andeditedCabalFile- the SHA256 of the modified Cabal file.
Setting them is done using the overrideCabal function. This is a piece of my
setup for a modified set of Haskell packages:
hl = nixpkgs.haskell.lib.compose; hsPkgs = nixpkgs.haskell.packages.ghc963.override { overrides = newpkgs: oldpkgs: { openapi3 = hl.overrideCabal (drv: { revision = "4"; editedCabalFile = "sha256-a5C58iYrL7eAEHCzinICiJpbNTGwiOFFAYik28et7fI="; }) (oldpkgs.callHackageDirect { pkg = "openapi3"; ver = "3.2.3"; sha256 = "sha256-0F16o3oqOB5ri6KBdPFEFHB4dv1z+Pw6E5f1rwkqwi8="; } { });
It's not very ergonomic, and I think an extended version of callHackageDirect
would make sense.
Bending Warp
In the past I've noticed that Warp both writes to stdout at times and produces
some default HTTP responses, but I've never bothered taking the time to look up
what possibilities it offers to changes this behaviour. I've also always thought
that I ought to find out how Warp handles signals.
If you wonder why this would be interesting to know there are three main points:
- The environments where the services run are set up to handle structured
logging. In our case it should be JSONL written to
stdout, i.e. one JSON object per line. - We've decided that the error responses we produce in our code should be JSON, so it's irritating to have to document some special cases where this isn't true just because Warp has a few default error responses.
- Signal handling is, IMHO, a very important part of writing a service that runs well in k8s as it uses signals to handle the lifetime of pods.
Looking through the Warp API
Browsing through the API documentation for Warp it wasn't too difficult to find the interesting pieces, and that Warp follows a fairly common pattern in Haskell libraries
- There's a function called
runSettingsthat takes an argument of typeSettings. - The default settings are available in a variable called
defaultSettings(not very surprising). There are several functions for modifying the settings and they all have the same shape
setX :: X -> Settings -> Settings.
which makes it easy to chain them together.
- The functions I'm interested in now are
setOnException- the default handler,
defaultOnException, prints the exception tostdoutusing itsShowinstance setOnExceptionResponse- the default responses are produced by
defaultOnExceptionResponseand contain plain text response bodies setInstallShutdownHandler- the default behaviour is to wait for all ongoing requests and then shut done
setGracefulShutdownTimeout- sets the number of seconds to wait for ongoing requests to finnish, the default is to wait indefinitely
Some experimenting
In order to experiment with these I put together a small API using servant,
app, with a main function using runSettings and stringing together a bunch
of modifications to defaultSettings.
main :: IO () main = Log.withLogger $ \logger -> do Log.infoIO logger "starting the server" runSettings (mySettings logger defaultSettings) (app logger) Log.infoIO logger "stopped the server" where mySettings logger = myShutdownHandler logger . myOnException logger . myOnExceptionResponse
myOnException logs JSON objects (using the logging I've written about before,
here and here). It decides wether to log or not using
defaultShouldDisplayException, something I copied from defaultOnException.
myOnException :: Log.Logger -> Settings -> Settings myOnException logger = setOnException handler where handler mr e = when (defaultShouldDisplayException e) $ case mr of Nothing -> Log.warnIO logger $ lm $ "exception: " <> T.pack (show e) Just _ -> do Log.warnIO logger $ lm $ "exception with request: " <> T.pack (show e)
myExceptionResponse responds with JSON objects. It's simpler than
defaultOnExceptionResponse, but it suffices for my learning.
myOnExceptionResponse :: Settings -> Settings myOnExceptionResponse = setOnExceptionResponse handler where handler _ = responseLBS H.internalServerError500 [(H.hContentType, "application/json; charset=utf-8")] (encode $ object ["error" .= ("Something went wrong" :: String)])
Finally, myShutdownHandler installs a handler for SIGTERM that logs and then
shuts down.
myShutdownHandler :: Log.Logger -> Settings -> Settings myShutdownHandler logger = setInstallShutdownHandler shutdownHandler where shutdownAction = Log.infoIO logger "closing down" shutdownHandler closeSocket = void $ installHandler sigTERM (Catch $ shutdownAction >> closeSocket) Nothing
Conclusion
I really ought to have looked into this sooner, especially as it turns out that
Warp offers all the knobs and dials I could wish for to control these aspects of
its behaviour. The next step is to take this and put it to use in one of the
services at $DAYJOB
Getting Amazonka S3 to work with localstack
I'm writing this in case someone else is getting strange errors when trying to use amazonka-s3 with localstack. It took me rather too long finding the answer and neither the errors I got from Amazonka nor from localstack were very helpful.
The code I started with for setting up the connection looked like this
main = do awsEnv <- AWS.overrideService localEndpoint <$> AWS.newEnv AWS.discover -- do S3 stuff where localEndpoint = AWS.setEndpoint False "localhost" 4566
A few years ago, when I last wrote some Haskell to talk to S3 this was enough1, but now I got some strange errors.
It turns out there are different ways to address buckets and the default, which
is used by AWS itself, isn't used by localstack. The documentation of
S3AddressingStyle has more details.
So to get it to work I had to change the S3 addressing style as well and ended up with this code instead
main = do awsEnv <- AWS.overrideService (s3AddrStyle . localEndpoint) <$> AWS.newEnv AWS.discover -- do S3 stuff where localEndpoint = AWS.setEndpoint False "localhost" 4566 s3AddrStyle svc = svc {AWS.s3AddressingStyle = AWS.S3AddressingStylePath}
Footnotes:
That was before version 2.0 of Amazonka, so it did look slightly different, but overriding the endpoint was all that was needed.
Defining a formatter for Cabal files
For Haskell code I can use lsp-format-buffer and lsp-format-region to keep
my file looking nice, but I've never found a function for doing the same for
Cabal files. There's a nice command line tool, cabal-fmt, for doing it, but it
means having to jump to a terminal. It would of course be nicer to satisfy my
needs for aesthetics directly from Emacs. A few times I've thought of writing
the function myself, I mean how hard can it be? But then I've forgotten about it
until then next time I'm editing a Cabal file.
A few days ago I noticed emacs-reformatter popping up in my feeds. That removed all reasons to procrastinate. It turned out to be very easy to set up.
The package doesn't have a recipe for straight.el so it needs a :straight
section. Also, the naming of the file in the package doesn't fit the package
name, hence the slightly different name in the use-package declaration:1
(use-package reformatter :straight (:host github :repo "purcell/emacs-reformatter"))
Now the formatter can be defined
(reformatter-define cabal-format :program "cabal-fmt" :args '("/dev/stdin"))
in order to create functions for formatting, cabal-format-buffer and
cabal-format-region, as well as a minor mode for formatting on saving a Cabal
file.
Footnotes:
I'm sure it's possible to use :files to deal with this, but I'm not sure
how and my naive guess failed. It's OK to be like this until I figure it out
properly.
Some practical Haskell
As I'm nearing the end of my time with my current employer I thought I'd put together some bits of practical Haskell that I've put into production. We only have a few services in Haskell, and basically I've had to sneak them into production. I'm hoping someone will find something useful. I'd be even happier if I get pointers on how to do this even better.
Logging
I've written about that earlier in three posts:
Final exception handler
After reading about the uncaught exception handler in Serokell's article I've added the following snippet to all the services.
main :: IO () main = do ... originalHandler <- getUncaughtExceptionHandler setUncaughtExceptionHandler $ handle originalHandler . lastExceptionHandler logger ... lastExceptionHandler :: Logger -> SomeException -> IO () lastExceptionHandler logger e = do fatalIO logger $ lm $ "uncaught exception: " <> displayException e
Handling signals
To make sure the platform we're running our services on is happy with a service
it needs to handle SIGTERM, and when running it locally during development,
e.g. for manual testing, it's nice if it also handles SIGINT.
The following snippet comes from a service that needs to make sure that every
iteration of its processing is completed before shutting down, hence the IORef
that's used to signal whether procession should continue or not.
main :: IO () main = do ... cont <- newIORef True void $ installHandler softwareTermination (Catch $ sigHandler logger cont) Nothing void $ installHandler keyboardSignal (Catch $ sigHandler logger cont) Nothing ... sigHandler :: Logger -> IORef Bool -> IO () sigHandler logger cont = do infoIO logger "got a signal, shutting down" writeIORef cont False
Probes
Due to some details about how networking works in our platform it's currently not possible to use network-based probing. Instead we have to use files. There are two probes that are of interest
- A startup probe, existance of the file signals that the service has started as is about being processing.
- A progress probe, a timestamp signals the time the most recent iteration of processing finished1.
I've written a little bit about the latter before in A little Haskell: epoch timestamp, but here I'm including both functions.
createPidFile :: FilePath -> IO () createPidFile fn = getProcessID >>= writeFile fn . show writeTimestampFile :: MonadIO m => FilePath -> m () writeTimestampFile fn = liftIO $ do getPOSIXTime >>= (writeFile fn . show) . truncate @_ @Int64 . (* 1000)
Footnotes:
The actual probing is then done using a command that compares the saved timestamp with the current time. As long as the difference is smaller than a threshold the probe succeeds.
Making an Emacs major mode for Cabal using tree-sitter
A few days ago I posted on r/haskell that I'm attempting to put together a Cabal grammar for tree-sitter. Some things are still missing, but it covers enough to start doing what I initially intended: experiment with writing an alternative Emacs major mode for Cabal.
The documentation for the tree-sitter integration is very nice, and several of
the major modes already have tree-sitter variants, called X-ts-mode where X
is e.g. python, so putting together the beginning of a major mode wasn't too
much work.
Configuring Emacs
First off I had to make sure the parser for Cabal was installed. The snippet for that looks like this1
(use-package treesit :straight nil :ensure nil :commands (treesit-install-language-grammar) :init (setq treesit-language-source-alist '((cabal . ("https://gitlab.com/magus/tree-sitter-cabal.git")))))
With that in place the parser is installed using M-x
treesit-install-language-grammar and choosing cabal.
After that I removed my configuration for haskell-mode and added the following
snippet to get my own major mode into my setup.
(use-package my-cabal-mode :straight (:type git :repo "git@gitlab.com:magus/my-emacs-pkgs.git" :branch "main" :files (:defaults "my-cabal-mode/*el")))
The major mode and font-locking
The built-in elisp documentation actually has a section on writing a major mode with tree-sitter, so it was easy to get started. Setting up the font-locking took a bit of trial-and-error, but once I had comments looking the way I wanted it was easy to add to the setup. Oh, and yes, there's a section on font-locking with tree-sitter in the documentation too. At the moment it looks like this
(defvar cabal--treesit-font-lock-setting (treesit-font-lock-rules :feature 'comment :language 'cabal '((comment) @font-lock-comment-face) :feature 'cabal-version :language 'cabal '((cabal_version _) @font-lock-constant-face) :feature 'field-name :language 'cabal '((field_name) @font-lock-keyword-face) :feature 'section-name :language 'cabal '((section_name) @font-lock-variable-name-face)) "Tree-sitter font-lock settings.") ;;;###autoload (define-derived-mode my-cabal-mode fundamental-mode "My Cabal" "My mode for Cabal files" (when (treesit-ready-p 'cabal) (treesit-parser-create 'cabal) ;; set up treesit (setq-local treesit-font-lock-feature-list '((comment field-name section-name) (cabal-version) () ())) (setq-local treesit-font-lock-settings cabal--treesit-font-lock-setting) (treesit-major-mode-setup))) ;;;###autoload (add-to-list 'auto-mode-alist '("\\.cabal\\'" . my-cabal-mode))
Navigation
One of the reasons I want to experiment with tree-sitter is to use it for code
navigation. My first attempt is to translate haskell-cabal-section-beginning
(in haskell-mode, the source) to using tree-sitter. First a convenience
function to recognise if a node is a section or not
(defun cabal--node-is-section-p (n) "Predicate to check if treesit node N is a Cabal section." (member (treesit-node-type n) '("benchmark" "common" "executable" "flag" "library" "test_suite")))
That makes it possible to use treesit-parent-until to traverse the nodes until
hitting a section node
(defun cabal-goto-beginning-of-section () "Go to the beginning of the current section." (interactive) (when-let* ((node-at-point (treesit-node-at (point))) (section-node (treesit-parent-until node-at-point #'cabal--node-is-section-p)) (start-pos (treesit-node-start section-node))) (goto-char start-pos)))
And the companion function, to go to the end of a section is very similar
(defun cabal-goto-end-of-section () "Go to the end of the current section." (interactive) (when-let* ((node-at-point (treesit-node-at (point))) (section-node (treesit-parent-until node-at-point #'cabal--node-is-section-p)) (end-pos (treesit-node-end section-node))) (goto-char end-pos)))
Footnotes:
I'm using straight.el and use-package in my setup, but hopefully the
snippets can easily be converted to other ways of configuring Emacs.
Logging with class
In two previous posts I've described how I currently compose log messages and how I do the actual logging. This post wraps up this particular topic for now with a couple of typeclasses, a default implementation, and an example showing how I use them.
The typeclasses
First off I want a monad for the logging itself. It's just a collection of
functions taking a LogMsg and returning unit (in a monad).
class Monad m => LoggerActions m where debug :: LogMsg -> m () info :: LogMsg -> m () warn :: LogMsg -> m () err :: LogMsg -> m () fatal :: LogMsg -> m ()
In order to provide a default implementation I also need a way to extract the logger itself.
class Monad m => HasLogger m where getLogger :: m Logger
Default implementation
Using the two typeclasses above it's now possible to define a type with an
implementation of LoggerActions that is usable with deriving
via.
newtype StdLoggerActions m a = MkStdZLA (m a) deriving (Functor, Applicative, Monad, MonadIO, HasLogger)
And its implementattion of LoggerActions looks like this:
instance (HasLogger m, MonadIO m) => LoggerActions (StdLoggerActions m) where debug msg = getLogger >>= flip debugIO msg info msg = getLogger >>= flip infoIO msg warn msg = getLogger >>= flip warnIO msg err msg = getLogger >>= flip errIO msg fatal msg = getLogger >>= flip fatalIO msg
An example
Using the definitions above is fairly straight forward. First a type the derives
its implementaiton of LoggerActions from StdLoggerActions.
newtype EnvT a = EnvT {runEnvT :: ReaderT Logger IO a} deriving newtype (Functor, Applicative, Monad, MonadIO, MonadReader Logger) deriving (LoggerActions) via (StdLoggerActions EnvT)
In order for it to work, and compile, it needs an implementation of HasLogger too.
instance HasLogger EnvT where getLogger = ask
All that's left is a function using a constraint on LoggerActions (doStuff)
and a main function creating a logger, constructing an EnvT, and then
running doStuff in it.
doStuff :: LoggerActions m => m () doStuff = do debug "a log line" info $ "another log line" #+ ["extras" .= (42 :: Int)] main :: IO () main = withLogger $ \logger -> runReaderT (runEnvT doStuff) logger
A take on logging
In my previous post I described a type, with instances and a couple of useful
functions for composing log messages. To actually make use of that there's a bit
more needed, i.e. the actual logging. In this post I'll share that part of the
logging setup I've been using in the Haskell services at $DAYJOB.
The logger type
The logger will be a wrapper around fast-logger's FastLogger, even though
that's not really visible.
newtype Logger = Logger (LogMsg -> IO ())
It's nature as a wrapper makes it natural to follow the API of fast-logger, with
some calls to liftIO added.
newLogger :: MonadIO m => m (Logger, m ()) newLogger = liftIO $ do (fastLogger, cleanUp) <- newFastLogger $ LogStdout defaultBufSize pure (Logger (fastLogger . toLogStr @LogMsg), liftIO cleanUp)
The implementation of withLogger is pretty much a copy of what I found in
fast-logger, just adapted to the newLogger above.
withLogger :: (MonadMask m, MonadIO m) => (Logger -> m ()) -> m () withLogger go = bracket newLogger snd (go . fst)
Logging functions
All logging functions will follow the same pattern so it's easy to break out the common parts.
logIO :: MonadIO m => Text -> Logger -> LogMsg -> m () logIO lvl (Logger ls) msg = do t <- formatTime defaultTimeLocale "%y-%m-%dT%H:%M:%S%03QZ" <$> liftIO getCurrentTime let bmsg = "" :# [ "correlation-id" .= ("no-correlation-id" :: Text) , "timestamp" .= t , "level" .= lvl ] liftIO $ ls $ bmsg <> msg
With that in place the logging functions become very short and sweet.
debugIO, infoIO, warnIO, errIO, fatalIO :: MonadIO m => Logger -> LogMsg -> m () debugIO = logIO "debug" infoIO = logIO "info" warnIO = logIO "warn" errIO = logIO "error" fatalIO = logIO "fatal"
Simple example of usage
A very simple example showing how it could be used would be something like this
main :: IO () main = withLogger $ \logger -> do debugIO logger "a log line" infoIO logger $ "another log line" #+ ["extras" .= (42 :: Int)]
A take on log messages
At $DAYJOB we use structured logging with rather little actual structure, the only rules are
- Log to
stdout. - Log one JSON object per line.
- The only required fields are
message- a human readable string describing the eventlevel- the severity of the event,debug,info,warn,error, orfatal.timestamp- the time of the eventcorrelation-id- an ID passed between services to allow to find related events
Beyond that pretty much anything goes, any other fields that are useful in that service, or even in that one log message is OK.
My first take was very ad-hoc, mostly becuase there were other parts of the question "How do I write a service in Haskell, actually?" that needed more attention – then I read Announcing monad-logger-aeson: Structured logging in Haskell for cheap. Sure, I'd looked at some of the logging libraries on Hackage but not really found anything that seemed like it would fit very well. Not until monad-logger-aeson, that is. Well, at least until I realised it didn't quite fit the rules we have.
It did give me some ideas of how to structure my current rather simple, but very awkward to use, current loggging code. This is what I came up with, and after using it in a handful services I find it kind of nice to work with. Let me know what you think.
The log message type
I decided that a log message must always contain the text describing the event. It's the one thing that's sure to be known at the point where the developer writes the code to log an event. All the other mandatory parts can, and probably should as far as possible, be added by the logging library itself. So I ended up with this type.
data LogMsg = Text :# [Pair] deriving (Eq, Show)
It should however be easy to add custom parts at the point of logging, so I added an operator for that.
(#+) :: LogMsg -> [Pair] -> LogMsg (#+) (msg :# ps0) ps1 = msg :# (ps0 <> ps1)
The ordering is important, i.e. ps0 <> ps1, as aeson's object function will
take the last value for a field and I want to be able to give keys in a log
message new values by overwriting them later on.
Instances to use it with fast-logger
The previous logging code used fast-logger and it had worked really well so I
decided to stick with it. Making LogMsg and instance of ToLogStr is key, and
as the rules require logging of JSON objects it also needs to be an instance of
ToJSON.
instance ToJSON LogMsg where toJSON (msg :# ps) = object $ ps <> ["message" .= msg] instance ToLogStr LogMsg where toLogStr msg = toLogStr (encode msg) <> "\n"
Instance to make it easy to log a string
It's common to just want to log a single string and nothing else, so it's handy
if LogMsg is an instance of IsString.
instance IsString LogMsg where fromString msg = pack msg :# []
Combining log messages
When writing the previous logging code I'd regularly felt pain from the lack of
a nice way to combine log messages. With the definition of LogMsg above it's
not difficult to come up with reasonable instances for both Semigroup and
Monoid.
instance Semigroup LogMsg where "" :# ps0 <> msg1 :# ps1 = msg1 :# (ps0 <> ps1) msg0 :# ps0 <> "" :# ps1 = msg0 :# (ps0 <> ps1) msg0 :# ps0 <> msg1 :# ps1 = (msg0 <> " - " <> msg1) :# (ps0 <> ps1) instance Monoid LogMsg where mempty = ""
In closing
What's missing above is the automatic handling of the remaining fields. I'll try to get back to that part soon. For now I'll just say that the log message API above made the implementation nice and straight forward.
Composing instances using deriving via
Today I watched the very good, and short, video from Tweag on how to Avoid boilerplate instances with -XDerivingVia. It made me realise that I've read about this before, but then the topic was on reducing boilerplate with MTL-style code.
Given that I'd forgotten about it I'm writing this mostly as a note to myself.
The example from the Tweag video, slightly changed
The code for making film ratings into a Monoid, when translated to the UK,
would look something like this:
{-# LANGUAGE DerivingVia #-}
{-# LANGUAGE GeneralizedNewtypeDeriving #-}
module DeriveMonoid where
newtype Supremum a = MkSup a
deriving stock (Bounded, Eq, Ord)
deriving newtype (Show)
instance Ord a => Semigroup (Supremum a) where
(<>) = max
instance (Bounded a, Ord a) => Monoid (Supremum a) where
mempty = minBound
data FilmClassification
= Universal
| ParentalGuidance
| Suitable12
| Suitable15
| Adults
| Restricted18
deriving stock (Bounded, Eq, Ord)
deriving (Monoid, Semigroup) via (Supremum FilmClassification)
Composing by deriving
First let's write up a silly class for writing to stdout, a single operation will do.
class Monad m => StdoutWriter m where writeStdoutLn :: String -> m ()
Then we'll need a type to attach the implementation to.
newtype SimpleStdoutWriter m a = SimpleStdoutWriter (m a) deriving (Functor, Applicative, Monad, MonadIO)
and of course an implementation
instance MonadIO m => StdoutWriter (SimpleStdoutWriter m) where writeStdoutLn = liftIO . putStrLn
Now let's create an app environment based on ReaderT and use deriving via to
give it an implementation of StdoutWriter via SimpleStdoutWriter.
newtype AppEnv a = AppEnv {unAppEnv :: ReaderT Int IO a} deriving ( Functor , Applicative , Monad , MonadIO , MonadReader Int ) deriving (StdoutWriter) via (SimpleStdoutWriter AppEnv)
Then a quick test to show that it actually works.
λ> runReaderT (unAppEnv $ writeStdoutLn "hello, world!") 0 hello, world!
Patching in Nix
Today I wanted to move one of my Haskell projects to GHC 9.2.4 and found that
envy didn't compile due to an upper bound on its dependency on bytestring, it
didn't allow 0.11.*.
After creating a PR I decided I didn't want to wait for upstream so instead I
started looking into options for patching the source of a derivation of a
package from Hackage. In the past I've written about building Haskell packages
from GitHub and an older one were I used callHackageDirect to build Haskell
packages from Hackage. I wasn't sure how to patch up a package from Hackage
though, but after a bit of digging through haskell-modules I found appendPatch.
The patch wasn't too hard to put together once I recalled the name of the patch
queue tool I used regularly years ago, quilt. I put the resulting patch in the
nix folder I already had, and the full override ended up looking like this
... hl = haskell.lib; hsPkgs = haskell.packages.ghc924; extraHsPkgs = hsPkgs.override { overrides = self: super: { envy = hl.appendPatch (self.callHackageDirect { pkg = "envy"; ver = "2.1.0.0"; sha256 = "sha256-yk8ARRyhTf9ImFJhDnVwaDiEQi3Rp4yBvswsWVVgurg="; } { }) ./nix/envy-fix-deps.patch; }; }; ...
A little Haskell: epoch timestamp
A need of getting the current UNIX time is something that comes up every now and then. Just this week I needed it in order to add a k8s liveness probe1.
While it's often rather straight forward to get the Unix time as an integer in other languages2, in Haskell there's a bit of type tetris involved.
- getPOSIXTime gives me a POSIXTime, which is an alias for NominalDiffTime.
NominalDiffTimeimplements RealFrac and can thus be converted to anything implementing Integral (I wanted it asInt64).NominalDiffTimealso implements Num, so if the timestamp needs better precision than seconds it's easy to do (I needed milliseconds).
The combination of the above is something like
truncate <$> getPOSIXTime
In my case the full function of writing the timestamp to a file looks like this
writeTimestampFile :: MonadIO m => Path Abs File -> m () writeTimestampFile afn = liftIO $ do truncate @_ @Int64 . (* 1000) <$> getPOSIXTime >>= writeFile (fromAbsFile afn) . show
Footnotes:
Over the last few days I've looked into k8s probes. Since we're using Istio TCP probes are of very limited use, and as the service in question doesn't offer an HTTP API I decided to use a liveness command that checks that the contents of a file is a sufficiently recent epoch timestamp.
Rust's Chrono package has Utc.timestamp(t). Python has time.time(). Golang has Time.Unix.
Simple nix flake for Haskell development
Recently I've moved over to using flakes in my Haskell development projects. It took me a little while to arrive at a pattern a flake for Haskell development that I like. I'm hoping sharing it might help others when doing the same change
{ inputs = { nixpkgs.url = "github:nixos/nixpkgs"; flake-utils.url = "github:numtide/flake-utils"; }; outputs = { self, nixpkgs, flake-utils }: flake-utils.lib.eachDefaultSystem (system: with nixpkgs.legacyPackages.${system}; let t = lib.trivial; hl = haskell.lib; name = "project-name"; project = devTools: # [1] let addBuildTools = (t.flip hl.addBuildTools) devTools; in haskellPackages.developPackage { root = lib.sourceFilesBySuffices ./. [ ".cabal" ".hs" ]; name = name; returnShellEnv = !(devTools == [ ]); # [2] modifier = (t.flip t.pipe) [ addBuildTools hl.dontHaddock hl.enableStaticLibraries hl.justStaticExecutables hl.disableLibraryProfiling hl.disableExecutableProfiling ]; }; in { packages.pkg = project [ ]; # [3] defaultPackage = self.packages.${system}.pkg; devShell = project (with haskellPackages; [ # [4] cabal-fmt cabal-install haskell-language-server hlint ]); }); }
The main issue I ran into is getting a development shell out of
haskellPackages.developPackage, it requires returnShellEnv to be true.
Something that isn't too easy to find out. This means that the only solution
I've found to getting a development shell is to have separate expressions for
building and getting a shell. In the above flake the build expression, [3],
passes an empty list of development tools, the argument devTools at [1],
while the development shell expression, [4], passes in a list of tools needed
for development only. The decision of whether the expression is for building or
for a development shell, [2], then looks at the list of development tools
passed in.
Fallback of actions
In a tool I'm writing I want to load a file that may reside on the local disk, but if it isn't there I want to fetch it from the web. Basically it's very similar to having a cache and dealing with a miss, except in my case I don't populate the cache.
Let me first define the functions to play with
loadFromDisk :: String -> IO (Either String Int) loadFromDisk k@"bad key" = do putStrLn $ "local: " <> k pure $ Left $ "no such local key: " <> k loadFromDisk k = do putStrLn $ "local: " <> k pure $ Right $ length k loadFromWeb :: String -> IO (Either String Int) loadFromWeb k@"bad key" = do putStrLn $ "web: " <> k pure $ Left $ "no such remote key: " <> k loadFromWeb k = do putStrLn $ "web: " <> k pure $ Right $ length k
Discarded solution: using the Alternative of IO directly
It's fairly easy to get the desired behaviour but Alternative of IO is based
on exceptions which doesn't strike me as a good idea unless one is using IO
directly. That is fine in a smallish application, but in my case it makes sense
to use tagless style (or ReaderT pattern) so I'll skip exploring this option
completely.
First attempt: lifting into the Alternative of Either e
There's an instance of Alternative for Either e in version 0.5 of
transformers. It's deprecated and it's gone in newer versions of the library as
one really should use Except or ExceptT instead. Even if I don't think it's
where I want to end up, it's not an altogether bad place to start.
Now let's define a function using liftA2 (<|>) to make it easy to see what the
behaviour is
fallBack :: Applicative m => m (Either String res) -> m (Either String res) -> m (Either String res) fallBack = liftA2 (<|>)
λ> loadFromDisk "bad key" `fallBack` loadFromWeb "good key" local: bad key web: good key Right 8 λ> loadFromDisk "bad key" `fallBack` loadFromWeb "bad key" local: bad key web: bad key Left "no such remote key: bad key"
The first example shows that it falls back to loading form the web, and the
second one shows that it's only the last failure that survives. The latter part,
that only the last failure survives, isn't ideal but I think I can live with
that. If I were interested in collecting all failures I would reach for
Validation from validation-selective (there's one in validation that
should work too).
So far so good, but the next example shows a behaviour I don't want
λ> loadFromDisk "good key" `fallBack` loadFromWeb "good key" local: good key web: good key Right 8
or to make it even more explicit
λ> loadFromDisk "good key" `fallBack` undefined local: good key *** Exception: Prelude.undefined CallStack (from HasCallStack): error, called at libraries/base/GHC/Err.hs:79:14 in base:GHC.Err undefined, called at <interactive>:451:36 in interactive:Ghci4
There's no short-circuiting!1
The behaviour I want is of course that if the first action is successful, then the second action shouldn't take place at all.
It looks like either <|> is strict in its second argument, or maybe it's
liftA2 that forces it. I've not bothered digging into the details, it's enough
to observe it to realise that this approach isn't good enough.
Second attempt: cutting it short, manually
Fixing the lack of short-circuiting the evaluation after the first success isn't too difficult to do manually. Something like this does it
fallBack :: Monad m => m (Either String a) -> m (Either String a) -> m (Either String a) fallBack first other = do first >>= \case r@(Right _) -> pure r r@(Left _) -> (r <|>) <$> other
It does indeed show the behaviour I want
λ> loadFromDisk "bad key" `fallBack` loadFromWeb "good key" local: bad key web: good key Right 8 λ> loadFromDisk "bad key" `fallBack` loadFromWeb "bad key" local: bad key web: bad key Left "no such remote key: bad key" λ> loadFromDisk "good key" `fallBack` undefined local: good key Right 8
Excellent! And to switch over to use Validation one just have to switch
constructors, Right becomes Success and Left becomes Failure. Though
collecting the failures by concatenating strings isn't the best idea of course.
Switching to some other Monoid (that's the constraint on the failure type)
isn't too difficult.
fallBack :: (Monad m, Monoid e) => m (Validation e a) -> m (Validation e a) -> m (Validation e a) fallBack first other = do first >>= \case r@(Success _) -> pure r r@(Failure _) -> (r <|>) <$> other
Third attempt: pulling failures out to MonadPlus
After writing the fallBack function I still wanted to explore other solutions.
There's almost always something more out there in the Haskell eco system, right?
So I asked in the #haskell-beginners channel on the Functional Programming
Slack. The way I asked the question resulted in answers that iterates over a
list of actions and cutting at the first success.
The first suggestion had me a little confused at first, but once I re-organised the helper function a little it made more sense to me.
mFromRight :: MonadPlus m => m (Either err res) -> m res mFromRight = (either (const mzero) return =<<)
To use it put the actions in a list, map the helper above, and finally run
asum on it all2. I think it makes it a little clearer what happens if
it's rewritten like this.
firstRightM :: MonadPlus m => [m (Either err res)] -> m res firstRightM = asum . fmap go where go m = m >>= either (const mzero) return
λ> firstRightM [loadFromDisk "bad key", loadFromWeb "good key"] local: bad key web: good key 8 λ> firstRightM [loadFromDisk "good key", undefined] local: good key 8
So far so good, but I left out the case where both fail, because that's sort of the fly in the ointment here
λ> firstRightM [loadFromDisk "bad key", loadFromWeb "bad key"] local: bad key web: bad key *** Exception: user error (mzero)
It's not nice to be back to deal with exceptions, but it's possible to recover,
e.g. by appending <|> pure 0.
λ> firstRightM [loadFromDisk "bad key", loadFromWeb "bad key"] <|> pure 0 local: bad key web: bad key 0
However that removes the ability to deal with the situation where all actions
fail. Not nice! Add to that the difficulty of coming up with a good
MonadPlus instance for an application monad; one basically have to resort to
the same thing as for IO, i.e. to throw an exception. Also not nice!
Fourth attempt: wrapping in ExceptT to get its Alternative behaviour
This was another suggestion from the Slack channel, and it is the one I like the most. Again it was suggested as a way to stop at the first successful action in a list of actions.
firstRightM :: (Foldable t, Functor t, Monad m, Monoid err) => t (m (Either err res)) -> m (Either err res) firstRightM = runExceptT . asum . fmap ExceptT
Which can be used similarly to the previous one. It's also easy to write a
variant of fallBack for it.
fallBack :: (Monad m, Monoid err) => m (Either err res) -> m (Either err res) -> m (Either err res) fallBack first other = runExceptT $ ExceptT first <|> ExceptT other
λ> loadFromDisk "bad key" `fallBack` loadFromWeb "good key" local: bad key web: good key Right 8 λ> loadFromDisk "good key" `fallBack` undefined local: good key Right 8 λ> loadFromDisk "bad key" `fallBack` loadFromWeb "bad key" local: bad key web: bad key Left "no such local key: bad keyno such remote key: bad key"
Yay! This solution has the short-circuiting behaviour I want, as well as collecting all errors on failure.
Conclusion
I'm still a little disappointed that liftA2 (<|>) isn't short-circuiting as I
still think it's the easiest of the approaches. However, it's a problem that one
has to rely on a deprecated instance of Alternative for Either String,
but switching to use Validation would be only a minor change.
Manually writing the fallBack function, as I did in the second attempt,
results in very explicit code which is nice as it often reduces the cognitive
load for the reader. It's a contender, but using the deprecated Alternative
instance is problematic and introducing Validition, an arguably not very
common type, takes away a little of the appeal.
In the end I prefer the fourth attempt. It behaves exactly like I want and even
though ExpectT lives in transformers I feel that it (I pull it in via mtl)
is in such wide use that most Haskell programmers will be familiar with it.
One final thing to add is that the documentation of Validation is an excellent
inspiration when it comes to the behaviour of its instances. I wish that the
documentation of other packages, in particular commonly used ones like base,
transformers, and mtl, would be more like it.
Comments, feedback, and questions
Dustin Sallings
Dustin sent me a comment via email a while ago, it's now March 2022 so it's taken me embarrassingly long to publish it here.
I removed a bit from the beginning of the email as it doesn't relate to this post.
… a thing I've written code for before that I was reasonably pleased with. I have a suite of software for managing my GoPro media which involves doing some metadata extraction from images and video. There will be multiple transcodings of each medium with each that contains the metadata having it completely intact (i.e., low quality encodings do not lose metadata fidelity). I also run this on multiple machines and store a cache of Metadata in S3.
Sometimes, I've already processed the metadata on another machine. Often, I can get it from the lowest quality. Sometimes, there's no metadata at all. The core of my extraction looks like this:
ms <- asum [ Just . BL.toStrict <$> getMetaBlob mid, fv "mp4_low" (fn "low"), fv "high_res_proxy_mp4" (fn "high"), fv "source" (fn "src"), pure Nothing]
The first version grabs the processed blob from S3. The next three fetch (and process) increasingly larger variants of the uploaded media. The last one just gives up and says there's no metadata available (and memoizes that in the local DB and S3).
Some of these objects are in the tens of gigs, and I had a really bad internet connection when I first wrote this software, so I needed it to work.
Footnotes:
I'm not sure if it's a good term to use in this case as Wikipedia says it's for Boolean operators. I hope it's not too far a stretch to use it in this context too.
In the version of base I'm using there is no asum, so I simply copied
the implementation from a later version:
asum :: (Foldable t, Alternative f) => t (f a) -> f a asum = foldr (<|>) empty
Using lens to set a value based on another
I started writing a small tool for work that consumes YAML files and combines
the data into a single YAML file. To be specific it consumes YAML files
containing snippets of service specification for Docker Compose and it produces
a YAML file for use with docker-compose. Besides being useful to me, I thought
it'd also be a good way to get some experience with lens.
The first transformation I wanted to write was one that puts in the correct image name. So, only slightly simplified, it is transforming
panda: x-image: panda goat: x-image: goat tapir: image: incorrent x-image: tapir
into
panda: image: panda:latest x-image: panda goat: image: goat:latest x-image: goat tapir: image: tapir:latest x-image: tapir
That is, it creates a new key/value pair in each object based on the value of
x-image in the same object.
First approach
The first approach I came up with was to traverse the sub-objects and apply a
function that adds the image key.
setImage :: Value -> Value setImage y = y & members %~ setImg where setImg o = o & _Object . at "image" ?~ String (o ^. key "x-image" . _String <> ":latest")
It did make me wonder if this kind of problem, setting a value based on another value, isn't so common that there's a nicer solution to it. Perhaps coded up in a combinator that isn't mentioned in Optics By Example (or mabye I've forgot it was mentioned). That lead me to ask around a bit, which leads to approach two.
Second approach
Arguably there isn't much difference, it's still traversing the sub-objects and
applying a function. The function makes use of view being run in a monad and
ASetter being defined with Identity (a monad).
setImage' :: Value -> Value setImage' y = y & members . _Object %~ (set (at "image") . (_Just . _String %~ (<> ":latest")) =<< view (at "x-image"))
I haven't made up my mind on whether I like this better than the first. It's disappointingly similar to the first one.
Third approach
Then I it might be nice to split the fetching of x-image values from the
addition of image key/value pairs. By extracting with an index it's possible
to keep track of what sub-object each x-image value comes from. Then two steps
can be combined using foldl.
setImage'' :: Value -> Value setImage'' y = foldl setOne y vals where vals = y ^@.. members <. key "x-image" . _String setOne y' (objKey, value) = y' & key objKey . _Object . at "image" ?~ String (value <> ":latest")
I'm not convinced though. I guess I'm still holding out for a brilliant combinator that fits my problem perfectly.
Please point me to "the perfect solution" if you have one, or if you just have some general tips on optics that would make my code clearer, or shorter, or more elegant, or maybe just more lens-y.
The timeout manager exception
The other day I bumped the dependencies of a Haskell project at work and noticed a new exception being thrown:
Thread killed by timeout manager
After a couple of false starts (it wasn't the connection pool, nor was it servant) I realised that a better approach would be to look at the list of packages that were updated as part of the dependency bumping.1 Most of them I thought would be very unlikely sources of it, but two in the list stood out:
| Package | Pre | Post |
|---|---|---|
| unliftio | 0.2.14 | 0.2.18 |
| warp | 3.3.15 | 3.3.16 |
warp since the exception seemed to be thrown shortly after handling an HTTP
request, and unliftio since the exception was caught by the handler for
uncaught exceptions and its description contains "thread". Also, when looking at
the code changes in warp on GitHub2 I found that some of the changes
introduced was increased use of unliftio for async stuff. The changes contain
mentions of TimeoutThread and System.TimeManager. That sounded promising,
and it lead me to the TimeoutThread exception in time-manager.
With that knowledge I could quickly adjust the handler for uncaught exceptions
to not log TimeoutThread as fatal:
lastExceptionHandler :: LoggerSet -> SomeException -> IO () lastExceptionHandler logger e | Just TimeoutThread <- fromException e = return () | otherwise = do logFatalIoS logger $ pack $ "uncaught exception: " <> displayException e flushLogStr logger
I have to say it was a bit more work to arrive at this than I'd have liked. I reckon there are easier ways to track down the information I needed. So I'd love to hear what tricks and tips others have.
Footnotes:
As a bonus it gave me a good reason to reach for comm, a command that I
rarely use but for some reason always enjoy.
GitHub's compare feature isn't very easy to discover, but a URL like this https://github.com/yesodweb/wai/compare/warp-3.3.15…warp-3.3.16 (note the 3 dots!) does the trick.
A first look at HMock
The other day I found Chris Smith's HMock: First Rate Mocks in Haskell (link to
hackage) and thought it could be nice see if it can clear up some of the tests I
have in a few of the Haskell projects at work. All the projects follow the
pattern of defining custom monads for effects (something like final tagless)
with instances implemented on a stack of monads from MTL. It's a pretty standard
thing in Haskell I'd say, especially since the monad stack very often ends up
being ReaderT MyConfig IO.
I decided to try it first on a single such custom monad, one for making HTTP requests:
class Monad m => MonadHttpClient m where mHttpGet :: String -> m (Status, ByteString) mHttpPost :: (Typeable a, Postable a) => String -> a -> m (Status, ByteString)
Yes, the underlying implementation uses wreq, but I'm not too bothered by that
shining through. Also, initially I didn't have that Typeable a constraint on
mHttpPost, it got added after a short exchange about KnownSymbol with Chris.
To dip a toe in the water I thought I'd simply write tests for the two effects themselves. First of all there's an impressive list of extensions needed, and then the monad needs to be made mockable:
{-# LANGUAGE DataKinds #-} {-# LANGUAGE FlexibleInstances #-} {-# LANGUAGE GADTs #-} {-# LANGUAGE ImportQualifiedPost #-} {-# LANGUAGE MultiParamTypeClasses #-} {-# LANGUAGE RankNTypes #-} {-# LANGUAGE StandaloneDeriving #-} {-# LANGUAGE TemplateHaskell #-} {-# LANGUAGE TypeApplications #-} {-# LANGUAGE TypeFamilies #-} makeMockable ''MonadHttpClient
After that, writing a test with HMock for mHttpGet was fairly straight
forward, I could simply follow the examples in the package's documentation. I'm
using tasty for organising the tests though:
httpGetTest :: TestTree httpGetTest = testCase "Get" $ do (s, b) <- runMockT $ do expect $ MHttpGet "url" |-> (status200, "result") mHttpGet "url" status200 @=? s "result" @=? b
The effect for sending a POST request was slightly trickier, as can be seen in
the issue linked above, but with some help I came up with the following:
httpPostTest :: TestTree httpPostTest = testCase "Post" $ do (s, b) <- runMockT $ do expect $ MHttpPost_ (eq "url") (typed @ByteString anything) |-> (status201, "result") mHttpPost "url" ("hello" :: ByteString) status201 @=? s "result" @=? b
Next step
My hope is that using HMock will remove the need for creating a bunch of test implementations for the various custom monads for effects1 in the projects, thereby reducing the amount of test code overall. I also suspect that it will make the tests clearer and easier to read, as the behaviour of the mocks are closer to the tests using the mocks.
Footnotes:
Basically they could be looked at as hand-written mocks.
Working with Hedis
I'm now writing the second Haskell service using Redis to store data. There are a few packages on Hackage related to Redis but I only found 2 client libraries, redis-io and hedis. I must say I like the API of redis-io better, but it breaks a rule I hold very dear:
Libraries should never log, that's the responsibility of the application.
So, hedis it is. I tried using the API as is, but found it really cumbersome so looked around and after some inspiration from hedis-simple I came up with the following functions.
First a wrapper around a Redis function that put everything into ExceptionT
with a function that transforms a reply into an Exception.
lpush :: Exception e => (Reply -> e) -> ByteString -> [ByteString] -> ExceptionT Redis Integer lpush mapper key element = ExceptionT $ replyToExc <$> R.lpush key element where replyToExc = first (toException . mapper)
I found wrapping up functions like this is simple, but repetitive.
Finally I need a way to run the whole thing and unwrap it all back to IO:
runRedis :: Connection -> ExceptionT Redis a -> IO (Either SomeException a) runRedis conn = R.runRedis conn . runExceptionT
First contribution to nixpkgs.haskellPackages
Nothing much to be proud of, but yesterday I found out that servant-docs was marked broken in nixpkgs even though it builds just fine and this morning I decided to do something about it.
So, with the help of a post on the NixOS discourse I put together my first PR.
Barbie and KenJSON
After higher-kinded data (HKD) and barbies were mentioned in episode 35 of Haskell Weekly I've been wondering if it could be used in combination with aeson to do validation when implementing web services.
TLDR; I think it'd work, but I have a feeling I'd have to spend some more time on it to get an API with nice ergonomics.
Defining a type to play with
I opted to use barbies-th to save on the typing a bit. Defining a simple type holding a name and an age can then look like this
declareBareB [d| data Person = Person {name :: Text, age :: Int} |] deriving instance Show (Person Covered Identity) deriving instance Show (Person Covered Maybe) deriving instance Show (Person Covered (Either Text))
The two functions from the Barbies module documentation, addDefaults and
check, can then be written like this
addDefaults :: Person Covered Maybe -> Person Covered Identity -> Person Covered Identity addDefaults = bzipWith trans where trans m d = maybe d pure m check :: Person Covered (Either Text) -> Either [Text] (Person Covered Identity) check pe = case btraverse (either (const Nothing) (Just . Identity)) pe of Just pin -> Right pin Nothing -> Left $ bfoldMap (either (: []) (const [])) pe
I found it straight forward to define some instances and play with those functions a bit.
Adding in JSON
The bit that wasn't immediately obvious to me was how to use aeson to parse into
a type like Person Covered (Either Text).
First off I needed some data to test things out with.
bs0, bs1 :: BSL.ByteString bs0 = "{\"name\": \"the name\", \"age\": 17}" bs1 = "{\"name\": \"the name\", \"age\": true}"
To keep things simple I took baby steps, first I tried parsing into Person
Covered Identity. It turns out that the FromJSON instance from that doesn't
need much thought at all. (It's a bit of a pain to have to specify types in GHCi
all the time, so I'm throwing in a specialised decoding function for each type
too.)
instance FromJSON (Person Covered Identity) where parseJSON = withObject "Person" $ \o -> Person <$> o .: "name" <*> o .: "age" decodePI :: BSL.ByteString -> Maybe (Person Covered Identity) decodePI = decode
Trying it out on the test data gives the expected results
λ> let i0 = decodePI bs0
λ> i0
Just (Person {name = Identity "the name", age = Identity 17})
λ> let i1 = decodePI bs1
λ> i1
Nothing
So far so good! Moving onto Person Covered Maybe. I spent some time trying to
use the combinators in Data.Aeson for dealing with parser failures, but in the
end I had to resort to using <|> from Alternative.
instance FromJSON (Person Covered Maybe) where parseJSON = withObject "Person" $ \o -> Person <$> (o .: "name" <|> pure Nothing) <*> (o .: "age" <|> pure Nothing) decodePM :: BSL.ByteString -> Maybe (Person Covered Maybe) decodePM = decode
Trying that out I saw exactly the behaviour I expected, i.e. that parsing won't fail. (Well, at least not as long as it's a valid JSON object to being with.)
λ> let m0 = decodePM bs0
λ> m0
Just (Person {name = Just "the name", age = Just 17})
λ> let m1 = decodePM bs1
λ> m1
Just (Person {name = Just "the name", age = Nothing})
With that done I found that the instance for Person Covered (Either Text)
followed quite naturally. I had to spend a little time on getting the types
right to parse the fields properly. Somewhat disappointingly I didn't get type
errors when the behaviour of the code turned out to be wrong. I'm gussing
aeson's Parser was a little too willing to give me parser failures. Anyway, I
ended up with this instance
instance FromJSON (Person Covered (Either Text)) where parseJSON = withObject "Person" $ \o -> Person <$> ((Right <$> o .: "name") <|> pure (Left "A name is most needed")) <*> ((Right <$> o .: "age") <|> pure (Left "An integer age is needed")) decodePE :: BSL.ByteString -> Maybe (Person Covered (Either Text)) decodePE = decode
That does exhibit the behaviour I want
λ> let e0 = decodePE bs0
λ> e0
Just (Person {name = Right "the name", age = Right 17})
λ> let e1 = decodePE bs1
λ> e1
Just (Person {name = Right "the name", age = Left "An integer age is needed"})
In closing
I think everyone will agree that the FromJSON instances are increasingly
messy. I think that can be fixed by putting some thought into what a more
pleasing API should look like.
I'd also like to mix in validation beyond what aeson offers out-of-the-box,
which really only is "is the field present?" and "does the value have the
correct type?". For instance, Once we know there is a field called age, and
that it's an Int, then we might want to make sure it's non-negitive, or that
the person is at least 18. I'm guessing that wouldn't be too difficult.
Finally, I'd love to see examples of using HKDs for parsing/validation in the wild. It's probably easiest to reach me at @magthe@mastodon.technology.
Custom monad with servant and throwing errors
In the past I've always used scotty when writing web services. This was mostly due to laziness, I found working out how to use scotty a lot easier than servant, so basically I was being lazy. Fairly quickly I bumped into some limitations in scotty, but at first the workarounds didn't add too much complexity and were acceptable. A few weeks ago they started weighing on me though and I decided to look into servant and since I really liked what I found I've started moving all projects to use servant.
In several of the projects I've used tagless final style and defined a type
based on ReaderT holding configuration over IO, that is something like
newtype AppM a = AppM {unAppM : ReaderT Config IO a} deriving ( Functor, Applicative, Monad, MonadIO, MonadReader Config ) runAppM :: AppM a -> Config -> IO a runAppM app = runReaderT (unAppM app)
I found that servant is very well suited to this style through hoistServer and
there are several examples on how to use it with a ReaderT-based type like
above. The first one I found is in the servant cookbook. However, as I realised
a bit later, using a simple type like this doesn't make it easy to trigger
responses with status other than 200 OK. When I looked at the definition of
the type for writing handlers that ships with servant, Handler, I decided to
try to use the following type in my service
newtype AppM a = AppM {unAppM : ReaderT Config (ExceptT ServerError IO) a} deriving ( Functor, Applicative, Monad, MonadIO, MonadReader Config ) runAppM :: AppM a -> Config -> IO (Either ServerError a) runAppM app = runExceptT . runReaderT (unAppM app)
The natural transformation required by hoistServer can then be written like
nt :: AppM a -> Handler a nt x = liftIO (runAppM x cfg) >>= \case Right v -> pure v Left err -> throwError err
I particularly like how clearly this suggests a way to add custom errors if I want that.
- Swap out
ServerErrorfor my custom error type inAppM. - Write a function to transform my custom error type into a
ServerError,transformCustomError :: CustomError -> ServerError. - use
throwError $ transformCustomError errin theLeftbranch ofnt.
A slight complication with MonadUnliftIO
I was using unliftio in my service, and as long as I based my monad stack only
on ReaderT that worked fine. I even got the MonadUnliftIO instance for free
through automatic deriving. ExceptT isn't a stateless monad though, so using
unliftio is out of the question, instead I had to switch to MonadBaseControl
and the packages that work with it. Defining and instance of MonadBaseControl
looked a bit daunting, but luckily Handler has an instance of it that I used
as inspiration.
First off MonadBaseControl requires the type to also be an instance of
MonadBase. There's an explicit implementation for Handler, but I found that
it can be derived automatically, so I took the lazy route.
The instance of MonadBaseControl for AppM ended up looking like this
instance MonadBaseControl IO AppM where type StM AppM a = Either ServerError a liftBaseWith f = AppM (liftBaseWith (\g -> f (g . unAppM))) restoreM = AppM . restoreM
I can't claim to really understand what's going on in that definition, but I have Alexis King's article on Demystifying MonadBaseControl on my list of things to read.
Flycheck and HLS
I've been using LSP for most programming languages for a while now. HLS is
really very good now, but I've found that it doesn't warn on quite all things
I'd like it to so I find myself having to swap between the 'lsp and
'haskell-ghc checkers. However, since flycheck supports chaining checkers I
thought there must be a way to have both checkers active at the same time.
The naive approach didn't work due to load order of things in Spacemacs so I had to experiment a bit to find something that works.
The first issue was to make sure that HLS is available at all. I use shell.nix
together with direnv extensively and I had noticed that lsp-mode tried to load
HLS before direnv had put it in the $PATH. I think the
'lsp-beforeinitialize-hook is the hook to use for this:
(add-hook 'lsp-before-initialize-hook #'direnv-update-environment))
I made a several attempt to chain the checkers but kept on getting
errors due to the 'lsp checker not being defined yet. Another problem
I ran into was that the checkers were chained too late, resulting in
having to manually run flycheck-buffer on the first file I opened.
(Deferred loading is a brilliant thing, but make some things really
difficult to debug.) After quite a bit of experimenting and reading the
description of various hooks I did find something that works:
(with-eval-after-load 'lsp-mode (defun magthe:lsp-next-checker () (flycheck-add-next-checker 'lsp '(warning . haskell-ghc))) (add-hook 'lsp-lsp-haskell-after-open-hook #'magthe:lsp-next-checker))
Of course I have no idea if this is the easiest or most elegant solution but it does work for my testcases:
- Open a file in a project,
SPC p l- choose project - choose a Haskell file. - Open a project,
SPC p lfollowed byC-d, and then open a Haskell file.
Suggestions for improvements are more than welcome, of course.
Haskell, Nix and using packages from GitHub
The other day I bumped into what turned out to be a bug in Amazonka where
sockets weren't closed in a timely fashion and thus the process ran out of file
descriptors. Some more digging and an issue later I found that a fix most likely
already in place (mine was possibly a duplicate of an older issue). Now I only
had to verify if that was the case by using the most recent, and unreleased code
on the develop branch of Amazonka.
My first thought was to attempt to instruct Cabal to build the bits of Amazonka
I need by putting a few source-repository-package stanzas in my config. That
quickly started to look like a bit of a rabbit hole, so I decided to use Nix
instead. After finding the perfect SO post and looking up yet again how to do
overrides for Haskell I ran cabal2nix for the three packages I need:
cabal2nix --no-haddock --no-check --subpath amazonka \ git://github.com/brendanhay/amazonka.git > amazonka.nix cabal2nix --no-haddock --no-check --subpath core \ git://github.com/brendanhay/amazonka.git > amazonka-core.nix cabal2nix --no-haddock --no-check --subpath amazonka-sqs \ git://github.com/brendanhay/amazonka.git > amazonka-sqs.nix
The relevant part of the old Nix expression looked like this:
thePkg = haskellPackages.developPackage { root = lib.cleanSource ./.; name = name; modifier = (t.flip t.pipe) [hl.dontHaddock hl.enableStaticLibraries hl.justStaticExecutables hl.disableLibraryProfiling hl.disableExecutableProfiling]; };
After adding the overrides it looked like this
hp = haskellPackages.override { overrides = self: super: { amazonka-core = self.callPackage ./amazonka-core.nix {}; amazonka = self.callPackage ./amazonka.nix {}; amazonka-sqs = self.callPackage ./amazonka-sqs.nix {}; }; }; thePkg = hp.developPackage { root = lib.cleanSource ./.; name = name; modifier = (t.flip t.pipe) [hl.dontHaddock hl.enableStaticLibraries hl.justStaticExecutables hl.disableLibraryProfiling hl.disableExecutableProfiling]; };
After a somewhat longer-than-usual build I could verify that I had indeed bumped into the same issue and my issue was a duplicate.
Combining Amazonka and Conduit
Combining amazonka and conduit turned out to be easier than I had expected.
Here's an SNS sink I put together today
snsSink :: (MonadAWS m, MonadIO m) => T.Text -> C.ConduitT Value C.Void m () snsSink topic = do C.await >>= \case Nothing -> pure () Just msg -> do _ <- C.lift $ publishSNS topic (TL.toStrict $ TL.decodeUtf8 $ encode msg) snsSink topic
Putting it to use can be done with something like
foo = do ... awsEnv <- newEnv Discover runAWSCond awsEnv $ <source producing Value> .| snsSink topicArn where runAWSCond awsEnv = runResourceT . runAWS awsEnv . within Frankfurt . C.runConduit
X-Ray and WAI
For a while we've been planning on introducing AWS X-Ray into our system at work. There's official support for a few languages, but not too surprisingly Haskell isn't on that list. I found freckle/aws-xray-client on GitHub, which is so unofficial that it isn't even published on Hackage. While it looks very good, I suspect it does more than I need and since it lacks licensing information I decided to instead implement a version tailored to our needs.
As a first step I implemented a WAI middleware that wraps an HTTP request and reports the time it took to produce a response. Between the X-Ray Developer Guide and the code in Freckle's git repo it turned out to be fairly simple.
First off, this is the first step towards X-Ray nirvana, so all I'm aiming for
is minimal support. That means all I want is to send minimal X-Ray segments,
with the small addition that I want to support parent_id from the start.
The first step then is to parse the HTTP header containing the X-Ray information
– X-Amzn-Trace-Id. For now I'm only interested in two parts, Root and
Parent, so for simplicity's sake I use a tuple to keep them in. The idea is to
take the header's value, split on ; to get the parts, then split each part in
two, a key and a value, and put them into an association list ([(Text, Text)])
for easy lookup using, well lookup.
parseXRayTraceIdHdr :: Text -> Maybe (Text, Maybe Text) parseXRayTraceIdHdr hdr = do bits <- traverse parseHeaderComponent $ T.split (== ';') hdr traceId <- lookup "Root" bits let parent = lookup "Parent" bits pure (traceId, parent) parseHeaderComponent :: Text -> Maybe (Text, Text) parseHeaderComponent cmp = case T.split (== '=') cmp of [name, value] -> Just (name, value) _ -> Nothing
The start and end times for processing a request are also required. The docs say
that using at least millisecond resolution is a good idea, so I decided to do
exactly that. NominalDiffTime, which is what getPOSIXTime produces, supports
a resolution of picoseconds (though I doubt my system's clock does) which
requires a bit of (type-based) converting.
mkTimeInMilli :: IO Milli mkTimeInMilli = ndfToMilli <$> getPOSIXTime where ndfToMilli = fromRational . toRational
The last support function needed is one that creates the segment. Just
building the JSON object, using aeson's object, is enough at this
point.
mkSegment :: Text -> Text -> Milli -> Milli -> (Text, Maybe Text) -> Value mkSegment name id startTime endTime (root, parent) = object $ [ "name" .= name , "id" .= id , "trace_id" .= root , "start_time" .= startTime , "end_time" .= endTime ] <> p where p = maybe [] (\ v -> ["parent_id" .= v]) parent
Armed with all this, I can now put together a WAI middleware that
- records the start time of the call
- processes the request
- sends off the response and keeps the result of it
- records the end time
- parses the tracing header
- builds the segment prepended with the X-Ray daemon header
- sends the segment to the X-Ray daemon
traceId :: Text -> Middleware traceId xrayName app req sendResponse = do startTime <- mkTimeInMilli app req $ \ res -> do rr <- sendResponse res endTime <- mkTimeInMilli theId <- T.pack . (\ v -> showHex v "") <$> randomIO @Word64 let traceParts = (decodeUtf8 <$> requestHeaderTraceId req) >>= parseXRayTraceIdHdr segment = mkSegment xrayName theId startTime endTime <$> traceParts case segment of Nothing -> pure () Just segment' -> sendXRayPayload $ toStrict $ prepareXRayPayload segment' pure rr where prepareXRayPayload segment = let header = object ["format" .= ("json" :: String), "version" .= (1 :: Int)] in encode header <> "\n" <> encode segment sendXRayPayload payload = do addrInfos <- S.getAddrInfo Nothing (Just "127.0.0.1") (Just "2000") case addrInfos of [] -> pure () -- silently skip (xrayAddr:_) -> do sock <- S.socket (S.addrFamily xrayAddr) S.Datagram S.defaultProtocol S.connect sock (S.addrAddress xrayAddr) sendAll sock payload S.close sock
The next step will be to instrument the actual processing. The service I'm instrumenting is asynchronous, so all the work happens after the response has been sent. My plan for this is to use subsegments to record it. That means I'll have to
- keep the
Rootand ID (theIdintraceIdabove) for use in subsegments - keep the original tracing header, for use in outgoing calls
- make sure all outgoing HTTP calls include a tracing header with a proper
Parent - wrap all outgoing HTTP calls with time keeping and sending a subsegment to the X-Ray daemon
I'm saving that work for a rainy day though, or rather, for a day when I'm so upset at Clojure that I don't want to see another parenthesis.
Edit (2020-04-10): Corrected the segment field name for the parent ID, it
should be parent_id.
My ghcide build for Nix
I was slightly disappointed to find out that not all packages on Hackage that are marked as present in Nix(pkgs) actually are available. Quite a few of them are marked broken and hence not installable. One of these packages is ghcide.
There are of course expressions available for getting a working ghcide
executable installed, like ghcide-nix. However, since I have rather simple needs
for my Haskell projects I thought I'd play with my own approach to it.
What I care about is:
- availability of the development tools I use, at the moment it's mainly
ghcidebut I'm planning on making use of ormolu in the near future - pre-built packages
- ease of use
So, I put together ghcide-for-nix. It's basically just a constumized Nixpkgs
where the packages needed to un-break ghcide are present.
Usage is a simple import away:
import (builtins.fetchGit { name = "ghcide-for-nix"; url = https://github.com/magthe/ghcide-for-nix; rev = "927a8caa62cece60d9d66dbdfc62b7738d61d75f"; })
and it'll give you a superset of Nixpkgs. Pre-built packages are available on Cachix.
It's not sophisticated, but it's rather easy to use and suffices for my purposes.
Haskell, ghcide, and Spacemacs
The other day I read Chris Penner's post on Haskell IDE Support and thought I'd make an attempt to use it with Spacemacs.
After running stack build hie-bios ghcide haskell-lsp --copy-compiler-tool I
had a look at the instructions on using haskell-ide-engine with Spacemacs.
After a bit of trial and error I came up with these changes to my
~/.spacemacs:
(defun dotspacemacs/layers () (setq-default dotspacemacs-configuration-layers '( ... lsp (haskell :variables haskell-completion-backend 'lsp ) ...) ) )
(defun dotspacemacs/user-config () (setq lsp-haskell-process-args-hie '("exec" "ghcide" "--" "--lsp") lsp-haskell-process-path-hie "stack" lsp-haskell-process-wrapper-function (lambda (argv) (cons (car argv) (cddr argv))) ) (add-hook 'haskell-mode-hook #'lsp))
The slightly weird looking lsp-haskell-process-wrapper-function is removing
the pesky --lsp inserted by this line.
That seems to work. Though I have to say I'm not ready to switch from intero just yet. Two things in particular didn't work with =ghcide=/LSP:
- Switching from one the
Main.hsin one executable to theMain.hsof another executable in the same project didn't work as expected – I had hints and types in the first, but nothing in the second. - Jump to the definition of a function defined in the package didn't work – I'm not willing to use GNU GLOBAL or some other source tagging system.
Hedgehog on a REST API, part 3
In my previous post on using Hedgehog on a REST API, Hedgehog on a REST API, part 2 I ran the test a few times and adjusted the model to deal with the incorrect assumptions I had initially made. In particular, I had to adjust how I modelled the User ID. Because of the simplicity of the API that wasn't too difficult. However, that kind of completely predictable ID isn't found in all APIs. In fact, it's not uncommon to have completely random IDs in API (often they are UUIDs).
So, I set out to try to deal with that. I'm still using the simple API from the previous posts, but this time I'm pretending that I can't build the ID into the model myself, or, put another way, I'm capturing the ID from the responses.
The model state
When capturing the ID it's no longer possible to use a simple Map Int Text for
the state, because I don't actually have the ID until I have an HTTP response.
However, the ID is playing an important role in the constructing of a sequence
of actions. The trick is to use Var Int v instead of an ordinary Int. As I
understand it, and I believe that's a good enough understanding to make use of
Hedgehog possible, is that this way the ID is an opaque blob in the construction
phase, and it's turned into a concrete value during execution. When in the
opaque state it implements enough type classes to be useful for my purposes.
newtype State (v :: * -> *)= State (M.Map (Var Int v) Text) deriving (Eq, Show)
The API calls: add user
When taking a closer look at the Callback type not all the callbacks will get
the state in the same form, opaque or concrete, and one of them, Update
actually receives the state in both states depending on the phase of execution.
This has the most impact on the add user action. To deal with it there's a need
to rearrange the code a bit, to be specific, commandExecute can no longer
return a tuple of both the ID and the status of the HTTP response because the
update function can't reach into the tuple, which it needs to update the state.
That means the commandExecute function will have to do tests too. It is nice
to keep all tests in the callbacks, but by sticking a MonadTest m constraint
on the commandExecute it turns into a nice solution anyway.
addUser :: (MonadGen n, MonadIO m, MonadTest m) => Command n m State addUser = Command gen exec [ Update u ] where gen _ = Just $ AddUser <$> Gen.text (Range.linear 0 42) Gen.alpha exec (AddUser n) = do (s, ui) <- liftIO $ do mgr <- newManager defaultManagerSettings addReq <- parseRequest "POST http://localhost:3000/users" let addReq' = addReq { requestBody = RequestBodyLBS (encode $ User 0 n)} addResp <- httpLbs addReq' mgr let user = decode (responseBody addResp) :: Maybe User return (responseStatus addResp, user) status201 === s assert $ isJust ui (userName <$> ui) === Just n return $ userId $ fromJust ui u (State m) (AddUser n) o = State (M.insert o n m)
I found that once I'd come around to folding the Ensure callback into the
commandExecute function the rest fell out from the types.
The API calls: delete user
The other actions, deleting a user and getting a user, required only minor changes and the changes were rather similar in both cases.
Not the type for the action needs to take a Var Int v instead of just a plain
Int.
newtype DeleteUser (v :: * -> *) = DeleteUser (Var Int v) deriving (Eq, Show)
Which in turn affect the implementation of HTraversable
instance HTraversable DeleteUser where htraverse f (DeleteUser vi) = DeleteUser <$> htraverse f vi
Then the changes to the Command mostly comprise use of concrete in places
where the real ID is needed.
deleteUser :: (MonadGen n, MonadIO m) => Command n m State deleteUser = Command gen exec [ Update u , Require r , Ensure e ] where gen (State m) = case M.keys m of [] -> Nothing ks -> Just $ DeleteUser <$> Gen.element ks exec (DeleteUser vi) = liftIO $ do mgr <- newManager defaultManagerSettings delReq <- parseRequest $ "DELETE http://localhost:3000/users/" ++ show (concrete vi) delResp <- httpNoBody delReq mgr return $ responseStatus delResp u (State m) (DeleteUser i) _ = State $ M.delete i m r (State m) (DeleteUser i) = i `elem` M.keys m e _ _ (DeleteUser _) r = r === status200
Conclusion
This post concludes my playing around with state machines in Hedgehog for this time. I certainly hope I find the time to put it to use on some larger API soon. In particular I'd love to put it to use at work; I think it'd be an excellent addition to the integration tests we currently have.
Architecture of a service
Early this summer it was finally time to put this one service I've been working on into our sandbox environment. It's been running without hickups so last week I turned it on for production as well. In this post I thought I'd document the how and why of the service in the hope that someone will find it useful.
The service functions as an interface to external SMS-sending services, offering a single place to change if we find that we are unhappy with the service we're using.1 This service replaces an older one, written in Ruby and no one really dares touch it. Hopefully the Haskell version will prove to be a joy to work with over time.
Overview of the architecture
The service is split into two parts, one web server using scotty, and streaming data processing using conduit. Persistent storage is provided by a PostgreSQL database. The general idea is that events are picked up from the database, acted upon, which in turn results in other events which written to the database. Those are then picked up and round and round we go. The web service accepts requests, turns them into events and writes the to the database.
Hopefully this crude diagram clarifies it somewhat.
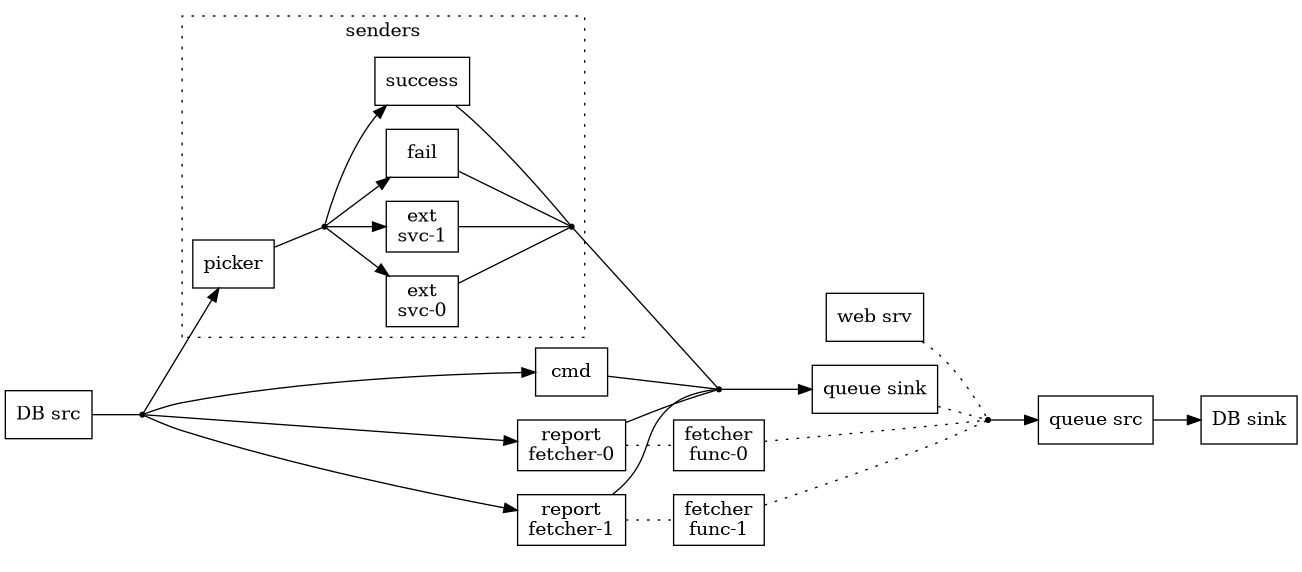
There are a few things that might need some explanation
In the past we've wanted to have the option to use multiple external SMS services at the same time. One is randomly chosen as the request comes in. There's also a possibility to configure the frequency for each external service.
Picker implements the random picking and I've written about that earlier in Choosing a conduit randomly.
Success and fail are dummy senders. They don't actually send anything, and the former succeeds at it while the latter fails. I found them useful for manual testing.
Successfully sending off a request to an external SMS service, getting status 200 back, doesn't actually mean that the SMS has been sent, or even that it ever will be. Due to the nature of SMS messaging there are no guarantees of timeliness at all. Since we are interested in finding out whether an SMS actually is sent a delayed action is scheduled, which will fetch the status of a sent SMS after a certain time (currently 2 minutes). If an SMS hasn't been sent after that time it might as well never be – it's too slow for our end-users.
This is what report-fetcher and fetcher-func do.
- The queue sink and queue src are actually
sourceTQueueandsinkTQueue. Splitting the stream like that makes it trivial to push in events by usingwriteTQueue. - I use
sequenceConduitsin order to send a single event to multiple =Conduit=s and then combine all their results back into a single stream. The ease with which this can be done in conduit is one of the main reasons why I choose to use it.2
Effects and tests
I started out writing everything based on a type like ReaderT <my cfg type> IO
and using liftIO for effects that needed lifting. This worked nicely while I
was setting up the basic structure of the service, but as soon as I hooked in
the database I really wanted to do some testing also of the effectful code.
After reading Introduction to Tagless Final and The ReaderT Design Patter, playing a bit with both approaches, and writing Tagless final and Scotty and The ReaderT design pattern or tagless final?, I finally chose to go down the route of tagless final. There's no strong reason for that decision, maybe it was just because I read about it first and found it very easy to move in that direction in small steps.
There's a split between property tests and unit tests:
- Data types, their monad instances (like JSON (de-)serialisation), pure functions and a few effects are tested using properties. I'm using QuickCheck for that. I've since looked a little closer at hedgehog and if I were to do a major overhaul of the property tests I might be tempted to rewrite them using that library instead.
- Most of the =Conduit=s are tested using HUnit.
Configuration
The service will be run in a container and we try to follow the 12-factor app rules, where the third one says that configuration should be stored in the environment. All previous Haskell projects I've worked on have been command line tools were configuration is done (mostly) using command line argument. For that I usually use optparse-applicative, but it's not applicable in this setting.
After a bit of searching on hackage I settled on etc. It turned out to be nice
an easy to work with. The configuration is written in JSON and only specifies
environment variables. It's then embedded in the executable using file-embed.
The only thing I miss is a ToJSON instance for Config – we've found it
quite useful to log the active configuration when starting a service and that
log entry would become a bit nicer if the message was JSON rather than the
(somewhat difficult to read) string that Config's Show instance produces.
Logging
There are two requirements we have when it comes to logging
- All log entries tied to a request should have a correlation ID.
- Log requests and responses
I've written about correlation ID before, Using a configuration in Scotty.
Logging requests and responses is an area where I'm not very happy with scotty.
It feels natural to solve it using middleware (i.e. using middleware) but the
representation, especially of responses, is a bit complicated so for the time
being I've skipped logging the body of both. I'd be most interested to hear of
libraries that could make that easier.
Data storage and picking up new events
The data stream processing depends heavily on being able to pick up when new
events are written to the database. Especially when there are more than one
instance running (we usually have at least two instance running in the
production environment). To get that working I've used postgresql-simple's
support for LISTEN and NOTIFY via the function getNotification.
When I wrote about this earlier, Conduit and PostgreSQL I got some really good feedback that made my solution more robust.
Delayed actions
Some things in Haskell feel almost like cheating. The light-weight threading
makes me confident that a forkIO followed by a threadDelay (or in my case,
the ones from unliftio) will suffice.
Footnotes:
It has happened in the past that we've changed SMS service after finding that they weren't living up to our expectations.
A while ago I was experimenting with other streaming libraries, but I gave up on getting re-combination to work – Zipping streams
Hedgehog on a REST API, part 2
This is a short follow-up to Hedgehog on a REST API where I actually run the tests in that post.
Fixing an issue with the model
The first issue I run into is
━━━ Main ━━━
✗ sequential failed after 18 tests and 1 shrink.
┏━━ tst/test-01.hs ━━━
89 ┃ getUser :: (MonadGen n, MonadIO m) => Command n m State
90 ┃ getUser = Command gen exec [ Require r
91 ┃ , Ensure e
92 ┃ ]
93 ┃ where
94 ┃ gen (State m) = case M.keys m of
95 ┃ [] -> Nothing
96 ┃ ks -> Just $ GetUser <$> Gen.element ks
97 ┃
98 ┃ exec (GetUser i) = liftIO $ do
99 ┃ mgr <- newManager defaultManagerSettings
100 ┃ getReq <- parseRequest $ "GET http://localhost:3000/users/" ++ show i
101 ┃ getResp <- httpLbs getReq mgr
102 ┃ let us = decode $ responseBody getResp :: Maybe [User]
103 ┃ return (status200 == responseStatus getResp, us)
104 ┃
105 ┃ r (State m) (GetUser i) = i `elem` M.keys m
106 ┃
107 ┃ e _ _ (GetUser _) (r, us) = do
108 ┃ r === True
109 ┃ assert $ isJust us
110 ┃ (length <$> us) === Just 1
┃ ^^^^^^^^^^^^^^^^^^^^^^^^^^
┃ │ Failed (- lhs =/= + rhs)
┃ │ - Just 0
┃ │ + Just 1
┏━━ tst/test-01.hs ━━━
118 ┃ prop_seq :: Property
119 ┃ prop_seq = property $ do
120 ┃ actions <- forAll $ Gen.sequential (Range.linear 1 10) initialState [addUser, deleteUser, getUser]
┃ │ Var 0 = AddUser ""
┃ │ Var 1 = GetUser 1
121 ┃ resetWS
122 ┃ executeSequential initialState actions
This failure can be reproduced by running:
> recheck (Size 17) (Seed 2158538972777046104 (-1442908127347265675)) sequential
✗ 1 failed.
It's easy to verify this using httpie:
$ http -p b POST :3000/users userId:=0 "userName=" { "userId": 0, "userName": "" } $ http -p b GET :3000/users/1 []
It's clear that my assumption that User ID starts at 1 is wrong. Luckily
fixing that isn't too difficult. Instead of defining the update function for
addUser as
u (State m) (AddUser n) _o = State $ M.insert k n m where k = succ $ foldl max 0 (M.keys m)
I define it as
u (State m) (AddUser n) _o = State $ M.insert k n m where k = case M.keys m of [] -> 0 ks -> succ $ foldl max 0 ks
The complete code at this point can be found here.
Fixing another issue with the model
With that fix in place another issue with the model shows up
━━━ Main ━━━
✗ sequential failed after 74 tests and 2 shrinks.
┏━━ tst/test-01.hs ━━━
91 ┃ getUser :: (MonadGen n, MonadIO m) => Command n m State
92 ┃ getUser = Command gen exec [ Require r
93 ┃ , Ensure e
94 ┃ ]
95 ┃ where
96 ┃ gen (State m) = case M.keys m of
97 ┃ [] -> Nothing
98 ┃ ks -> Just $ GetUser <$> Gen.element ks
99 ┃
100 ┃ exec (GetUser i) = liftIO $ do
101 ┃ mgr <- newManager defaultManagerSettings
102 ┃ getReq <- parseRequest $ "GET http://localhost:3000/users/" ++ show i
103 ┃ getResp <- httpLbs getReq mgr
104 ┃ let us = decode $ responseBody getResp :: Maybe [User]
105 ┃ return (status200 == responseStatus getResp, us)
106 ┃
107 ┃ r (State m) (GetUser i) = i `elem` M.keys m
108 ┃
109 ┃ e _ _ (GetUser _) (r, us) = do
110 ┃ r === True
111 ┃ assert $ isJust us
112 ┃ (length <$> us) === Just 1
┃ ^^^^^^^^^^^^^^^^^^^^^^^^^^
┃ │ Failed (- lhs =/= + rhs)
┃ │ - Just 0
┃ │ + Just 1
┏━━ tst/test-01.hs ━━━
120 ┃ prop_seq :: Property
121 ┃ prop_seq = property $ do
122 ┃ actions <- forAll $ Gen.sequential (Range.linear 1 10) initialState [addUser, deleteUser, getUser]
┃ │ Var 0 = AddUser ""
┃ │ Var 1 = DeleteUser 0
┃ │ Var 2 = AddUser ""
┃ │ Var 3 = GetUser 0
123 ┃ resetWS
124 ┃ executeSequential initialState actions
This failure can be reproduced by running:
> recheck (Size 73) (Seed 3813043122711576923 (-444438259649958339)) sequential
✗ 1 failed.
Again, verifying this using httpie shows what the issue is
$ http -p b POST :3000/users userId:=0 "userName=" { "userId": 0, "userName": "" } $ http -p b DELETE :3000/users/0 $ http -p b POST :3000/users userId:=0 "userName=" { "userId": 1, "userName": "" } $ http -p b GET :3000/users/0 []
In other words, the model assumes that the 0 User ID get's re-used.
To fix this I need a bigger change. The central bit is that the state is changed to keep track of the index more explicitly. That is, it changes from
newtype State (v :: * -> *)= State (M.Map Int Text) deriving (Eq, Show)
to
data State (v :: * -> *)= State Int (M.Map Int Text) deriving (Eq, Show)
That change does, quite obviously, require a bunch of other changes in the other functions dealing with the state. The complete file can be viewed here.
All is well, or is it?
After this the tests pass, so all is good in the world, right?
In the test I defined the property over rather short sequences of commands. What
happens if I increase the (maximum) length of the sequences a bit? Instead using
Range.linear 1 10 I'll use Range.linear 1 1000. Well, besides taking
slightly longer to run I get another sequence of commands that triggers an
issue:
━━━ Main ━━━
✗ sequential failed after 13 tests and 29 shrinks.
┏━━ tst/test-01.hs ━━━
87 ┃ getUser :: (MonadGen n, MonadIO m) => Command n m State
88 ┃ getUser = Command gen exec [ Require r
89 ┃ , Ensure e
90 ┃ ]
91 ┃ where
92 ┃ gen (State _ m) = case M.keys m of
93 ┃ [] -> Nothing
94 ┃ ks -> Just $ GetUser <$> Gen.element ks
95 ┃
96 ┃ exec (GetUser i) = liftIO $ do
97 ┃ mgr <- newManager defaultManagerSettings
98 ┃ getReq <- parseRequest $ "GET http://localhost:3000/users/" ++ show i
99 ┃ getResp <- httpLbs getReq mgr
100 ┃ let us = decode $ responseBody getResp :: Maybe [User]
101 ┃ return (status200 == responseStatus getResp, us)
102 ┃
103 ┃ r (State _ m) (GetUser i) = i `elem` M.keys m
104 ┃
105 ┃ e _ _ (GetUser _) (r, us) = do
106 ┃ r === True
107 ┃ assert $ isJust us
108 ┃ (length <$> us) === Just 1
┃ ^^^^^^^^^^^^^^^^^^^^^^^^^^
┃ │ Failed (- lhs =/= + rhs)
┃ │ - Just 0
┃ │ + Just 1
┏━━ tst/test-01.hs ━━━
116 ┃ prop_seq :: Property
117 ┃ prop_seq = property $ do
118 ┃ actions <- forAll $ Gen.sequential (Range.linear 1 1000) initialState [addUser, deleteUser, getUser]
┃ │ Var 0 = AddUser ""
┃ │ Var 2 = AddUser ""
┃ │ Var 5 = AddUser ""
┃ │ Var 7 = AddUser ""
┃ │ Var 9 = AddUser ""
┃ │ Var 11 = AddUser ""
┃ │ Var 20 = AddUser ""
┃ │ Var 28 = AddUser ""
┃ │ Var 30 = AddUser ""
┃ │ Var 32 = AddUser ""
┃ │ Var 33 = AddUser ""
┃ │ Var 34 = AddUser ""
┃ │ Var 37 = AddUser ""
┃ │ Var 38 = AddUser ""
┃ │ Var 41 = AddUser ""
┃ │ Var 45 = AddUser ""
┃ │ Var 47 = GetUser 15
119 ┃ resetWS
120 ┃ executeSequential initialState actions
This failure can be reproduced by running:
> recheck (Size 12) (Seed 2976784816810995551 (-47094630645854485)) sequential
✗ 1 failed.
That is, after inserting 16 users, we don't see any user when trying to get that 16th user (User ID 15). That's a proper bug in the server.
As a matter of fact, this is the bug I put into the server and was hoping to find. In particular, I wanted hedgehog to find the minimal sequence leading to this bug.1 Which it clearly has!
Footnotes:
If you recall from the previous post, I was interested in the integrated shrinking offered by hedgehog.
Hedgehog on a REST API
Last year I wrote a little bit about my attempt to use QuickCheck to test a REST API. Back then I got as far as generating test programs, running them, and validating an in-test model against the observed behaviour of the web service under test. One thing that I didn't implement was shrinking. I had some ideas, and got some better ideas in a comment on that post, but I've not taken the time to actually sit down and work it out. Then, during this spring, a couple of blog posts from Oskar Wickström (intro, part 1, part 2) made me aware of another library for doing property-based testing, hedgehog. It differs quite a bit from QuickCheck, most notably the way it uses to generate random data, and, this is the bit that made me sit up and pay attention, it has integrated shrinking.
My first plan was to use the same approach as I used with QuickCheck, but after finding out that there's explicit support for state machine tests everything turned out to be a bit easier than I had expected.
Well, it still wasn't exactly easy to work out the details, but the registry example in the hedgehog source repo together with a (slightly dated) example I managed to work it out (I think).
The REST API
The API is the same as in the post on using QuickCheck, with one little
difference, I've been lazy when implementing GET /users/:id and return a list
of users (that makes it easy to represent a missing :id).
| Method | Route | Example in | Example out |
|---|---|---|---|
POST |
/users |
{"userId": 0, "userName": "Yogi Berra"} |
{"userId": 42, "userName": "Yogi Berra"} |
DELETE |
/users/:id |
||
GET |
/users |
[0,3,7] |
|
GET |
/users/:id |
[{"userId": 42, "userName": "Yogi Berra"}] |
|
GET |
/users/:id |
[] (when there's no user with :id) |
|
POST |
/reset |
The model state
Just like last time I'm using as simple a model as I think I can get away with, based on the API above:
newtype State (v :: * -> *)= State (M.Map Int Text) deriving (Eq, Show) initialState :: State v initialState = State M.empty
That extra v is something that hedgehog requires. Why? I don't really know,
and luckily I don't have to care to make it all work. One thing though, the
language pragma KindSignatures is necessary to use that kind of syntax.
Representing API calls
Representing an API call requires three things
- a type
- an implementation of
HTraversablefor the type - a function producing a
Commandfor the type
I represent the three API calls with these three types
newtype AddUser (v :: * -> *) = AddUser Text deriving (Eq, Show) newtype DeleteUser (v :: * -> *) = DeleteUser Int deriving (Eq, Show) newtype GetUser (v :: * -> *) = GetUser Int deriving (Eq, Show)
Again that v pops up, but as with the model state, there's no need to pay any
attention to it.
For the implementation of HTraversable I was greatly helped by the registry
example. Their implementations are fairly straight forward, which is a good
thing since the need for them is internal to hedgehog.
instance HTraversable AddUser where htraverse _ (AddUser n) = AddUser <$> pure n instance HTraversable DeleteUser where htraverse _ (DeleteUser i) = DeleteUser <$> pure i instance HTraversable GetUser where htraverse _ (GetUser i) = GetUser <$> pure i
Once these two things are out of the way we get to the meat of the
implementation of the API calls, a function creating a Command instance for
each type of API call. The exact type for all three functions will be
(MonadGen n, MonadIO m) => Command n m State
which doesn't say a whole lot, I think. After reading the documentation I found
it a little clearer, but the two examples, state machine testing and registry,
was what cleared things up for me.1 In an attempt at being overly explicit I
wrote these functions in the same style. This is what it ended up looking like
for the AddUser type:
addUser :: (MonadGen n, MonadIO m) => Command n m State addUser = Command gen exec [ Update u , Ensure e ] where gen _ = Just $ AddUser <$> Gen.text (Range.linear 0 42) Gen.alpha exec (AddUser n) = liftIO $ do mgr <- newManager defaultManagerSettings addReq <- parseRequest "POST http://localhost:3000/users" let addReq' = addReq { requestBody = RequestBodyLBS (encode $ User 0 n)} addResp <- httpLbs addReq' mgr let user = decode (responseBody addResp) :: Maybe User return (responseStatus addResp, user) u (State m) (AddUser n) _o = State $ M.insert k n m where k = succ $ foldl max 0 (M.keys m) e _ _ (AddUser n) (r, ui) = do r === status201 assert $ isJust ui (userName <$> ui) === Just n
Piece by piece:
genis the generator of data. It takes one argument, the current state, but forAddUserI have no use for it. The user name is generated using a generator forText, and rather arbitrarily I limit the names to 42 characters.execis the action that calls the web service. Here I'm using http-client to make the call and aeson to parse the response into aUser. It produces output.uis a function for updating the model state. It's given the current state, the command and the output. All I need to to do forAddUseris to pick auserIdand associate it with the generated name.eis a function for checking post-conditions, in other words checking properties that must hold afterexechas run and the state has been updated. It's given four arguments, the previous state, the updated state, the command and the output. The tests here are on the HTTP response code and the returned user name. I think that will do for the time being.
The function for DeleteUser follows the same pattern
deleteUser :: (MonadGen n, MonadIO m) => Command n m State deleteUser = Command gen exec [ Update u , Require r , Ensure e ] where gen (State m) = case M.keys m of [] -> Nothing ks -> Just $ DeleteUser <$> Gen.element ks exec (DeleteUser i) = liftIO $ do mgr <- newManager defaultManagerSettings delReq <- parseRequest $ "DELETE http://localhost:3000/users/" ++ show i delResp <- httpNoBody delReq mgr return $ responseStatus delResp u (State m) (DeleteUser i) _ = State $ M.delete i m r (State m) (DeleteUser i) = i `elem` M.keys m e _ _ (DeleteUser _) r = r === status200
I think only two pieces need further explanation:
genonly returns aDeleteUserwith an index actually present in the model state. If there are no users in the model thenNothingis returned. As far as I understand that means that generated programs will only make calls to delete existing users.2ris a pre-condition that programs only delete users that exist. At first I had skipped this pre-condition, thinking that it'd be enough to havegenonly create delete calls for existing users. However, after reading the documentation ofCommandandCallbacka bit more closely I realised that I might need a pre-condition to make sure that this holds true also while shrinking.
The final function, for GetUser requires no further explanation so I only
present it here
getUser :: (MonadGen n, MonadIO m) => Command n m State getUser = Command gen exec [ Require r , Ensure e ] where gen (State m) = case M.keys m of [] -> Nothing ks -> Just $ GetUser <$> Gen.element ks exec (GetUser i) = liftIO $ do mgr <- newManager defaultManagerSettings getReq <- parseRequest $ "GET http://localhost:3000/users/" ++ show i getResp <- httpLbs getReq mgr let us = decode $ responseBody getResp :: Maybe [User] return (status200 == responseStatus getResp, us) r (State m) (GetUser i) = i `elem` M.keys m e _ _ (GetUser _) (r, us) = do r === True assert $ isJust us (length <$> us) === Just 1
The property and test
It looks like there are two obvious top-level properties
- the web service works as expected when all calls are made one at a time (sequential), and
- the web service works as expected when all calls are made in parallel.
Hedgehog provides two pairs of functions for this
- a
sequentialgenerator withexecuteSequential, and - a
parallelgenerator withexecuteParallel.
I started with the former only
prop_seq :: Property prop_seq = property $ do actions <- forAll $ Gen.sequential (Range.linear 1 10) initialState [addUser, deleteUser, getUser] resetWS executeSequential initialState actions
This first creates a generator of programs of at most length 103, then
turning that into a Sequential which can be passed to executeSequential to
turn into a Property.
The function resetWS clears out the web service to make sure that the tests
start with a clean slate each time. Its definition is
resetWS :: MonadIO m => m () resetWS = liftIO $ do mgr <- newManager defaultManagerSettings resetReq <- parseRequest "POST http://localhost:3000/reset" void $ httpNoBody resetReq mgr
The final bit is the main function, which I wrote like this
main :: IO () main = do res <- checkSequential $ Group "Main" [("sequential", prop_seq)] unless res exitFailure
That is, first run the property sequentially (checkSequential) and if that
fails exit with failure.
Running the test
When running the test fails and gives me a program that breaks the property, and exactly what fails:
━━━ Main ━━━
✗ sequential failed after 13 tests and 1 shrink.
┏━━ tst/test-01.hs ━━━
89 ┃ getUser :: (MonadGen n, MonadIO m) => Command n m State
90 ┃ getUser = Command gen exec [ Require r
91 ┃ , Ensure e
92 ┃ ]
93 ┃ where
94 ┃ gen (State m) = case M.keys m of
95 ┃ [] -> Nothing
96 ┃ ks -> Just $ GetUser <$> Gen.element ks
97 ┃
98 ┃ exec (GetUser i) = liftIO $ do
99 ┃ mgr <- newManager defaultManagerSettings
100 ┃ getReq <- parseRequest $ "GET http://localhost:3000/users/" ++ show i
101 ┃ getResp <- httpLbs getReq mgr
102 ┃ let us = decode $ responseBody getResp :: Maybe [User]
103 ┃ return (status200 == responseStatus getResp, us)
104 ┃
105 ┃ r (State m) (GetUser i) = i `elem` M.keys m
106 ┃
107 ┃ e _ _ (GetUser _) (r, us) = do
108 ┃ r === True
109 ┃ assert $ isJust us
110 ┃ (length <$> us) === Just 1
┃ ^^^^^^^^^^^^^^^^^^^^^^^^^^
┃ │ Failed (- lhs =/= + rhs)
┃ │ - Just 0
┃ │ + Just 1
┏━━ tst/test-01.hs ━━━
118 ┃ prop_seq :: Property
119 ┃ prop_seq = property $ do
120 ┃ actions <- forAll $ Gen.sequential (Range.linear 1 10) initialState [addUser, deleteUser, getUser]
┃ │ Var 0 = AddUser ""
┃ │ Var 1 = GetUser 1
121 ┃ resetWS
122 ┃ executeSequential initialState actions
This failure can be reproduced by running:
> recheck (Size 12) (Seed 6041776208714975061 (-2279196309322888437)) sequential
✗ 1 failed.
My goodness, that is pretty output!
Anyway, I'd say that the failing program has been shrunk to be minimal so I'd say that all in all this is a big step up from what I had earlier. Sure, using the hedgehog state machine API is slightly involved, but once worked out I find it fairly straight-forward and it most likely is written by people much more knowledgable than me and better than anything I could produce. Having to use generators explicitly (the hedgehog way) is neither easier nor more complicated than defining a few type class instances (the QuickCheck way). Finally, the integrated shrinking is rather brilliant and not having to implement that myself is definitely a big benefit.
Now I only have to fix the errors in the web service that the test reveal. This post is already rather long, so I'll keep that for a future post.
Footnotes:
There is still one thing that's unclear to me though, and that's how to get to the output in an update function.
Put another way, programs will never test how the web service behaves when asking for non-existing users. I think that, if I want to test that, I'll opt for using a separate API call type for it.
At least that's my understanding of the impact of Range.linear 1 10.
Comonadic builders, minor addition
When reading about Comonadic builders the other day I reacted to this comment:
The
comonadpackage has the Tracednewtypewrapper around the function(->). TheComonadinstance for thisnewtypegives us the desired behaviour. However, dealing with thenewtypewrapping and unwrapping makes our code noisy and truly harder to understand, so let's use theComonadinstance for the arrow(->)itself
So, just for fun I thought I work out the "noisy and truly harder" bits.
To begin with I needed two language extensions and two imports
{-# LANGUAGE OverloadedStrings#-} {-# LANGUAGE RecordWildCards #-} import Control.Comonad.Traced import Data.Text
After that I could copy quite a bit of stuff directly from the other post
Settingsdefinition- The
Semigroupinstance forSettings - The
Monoidinstance forSettings Projectdefinition
After this everything had only minor changes. First off the ProjectBuilder
type had to be changed to
type ProjectBuilder = Traced Settings Project
With that done the types of all the functions can actually be left as they are,
but of course the definitions have to modified. However, it turned out that the
necessary modifications were rather smaller than I had expected. First out
buildProject which I decided to call buildProjectW to make it possible to
keep the original code and the new code in the same file without causing name
clashes:
buildProjectW :: Text -> ProjectBuilder buildProjectW = traced . buildProject where buildProject projectName Settings{..} = Project { projectHasLibrary = getAny settingsHasLibrary , projectGitHub = getAny settingsGitHub , projectTravis = getAny settingsTravis , .. }
The only difference is the addition of traced . to wrap it up in the
newtype, the rest is copied straight from the original article.
The two simple project combinator functions, which I call hasLibraryBW and
gitHubBW, needed a bit of tweaking. In the original version combinators take a
builder which is an ordinary function, so it can just be called. Now however,
the function is wrapped in a newtype so a bit of unwrapping is necessary:
hasLibraryBW :: ProjectBuilder -> Project hasLibraryBW builder = runTraced builder $ mempty { settingsHasLibrary = Any True } gitHubBW :: ProjectBuilder -> Project gitHubBW builder = runTraced builder $ mempty { settingsGitHub = Any True }
Once again it's rather small differences from the code in the article.
As for the final combinator, which I call travisBW, actually needed no changes
at all. I only rewrote it using a when clause, because I prefer that style
over let:
travisBW :: ProjectBuilder -> Project travisBW builder = project { projectTravis = projectGitHub project } where project = extract builder
Finally, to show that this implementation hasn't really changed the behaviour
λ extract $ buildProjectW "travis" =>> travisBW Project { projectName = "travis" , projectHasLibrary = False , projectGitHub = False , projectTravis = False } λ extract $ buildProjectW "github-travis" =>> gitHubBW =>> travisBW Project { projectName = "github-travis" , projectHasLibrary = False , projectGitHub = True , projectTravis = True } λ extract $ buildProjectW "travis-github" =>> travisBW =>> gitHubBW Project { projectName = "travis-github" , projectHasLibrary = False , projectGitHub = True , projectTravis = True }
Conduit and PostgreSQL
For a while now I've been playing around with an event-drive software design
(EDA) using conduit for processing of events. For this post the processing can
basically be viewed as the following diagram
+-----------+ +------------+ +---------+
| | | | | |
| PG source |-->| Processing |-->| PG sink |
| | | | | |
+-----------+ +------------+ +---------+
^ |
| +------+ |
| | | |
| | PG | |
+------------| DB |<-----------+
| |
+------+
I started out looking for Conduit components for PostgreSQL on Hackage but
failed to find something fitting so I started looking into writing them myself
using postgresql-simple.
The sink wasn't much of a problem, use await to get an event (a tuple) and
write it to the database. My almost complete ignorance of using databases
resulted in a first version of the source was rather naive and used
busy-waiting. Then I stumbled on PostgreSQL's support for notifications through
the LISTEN and NOTIFY commands. I rather like the result and it seems to
work well.1
It looks like this
import Control.Monad.IO.Class (MonadIO, liftIO) import Data.Aeson (Value) import qualified Data.Conduit as C import qualified Data.Conduit.Combinators as CC import Data.Text (Text) import Data.Time.Clock (UTCTime) import Data.UUID (UUID) import Database.PostgreSQL.Simple (Connection, Only(..), execute, execute_, query) import Database.PostgreSQL.Simple.Notification (getNotification) fst8 :: (a, b, c, d, e, f, g, h) -> a fst8 (a, _, _, _, _, _, _, _) = a dbSource :: MonadIO m => Connection -> Int -> C.ConduitT () (Int, UTCTime, Int, Int, Bool, UUID, Text, Value) m () dbSource conn ver = do res <- liftIO $ query conn "SELECT * from events where id > (?) ORDER BY id" (Only ver) case res of [] -> do liftIO $ execute_ conn "LISTEN MyEvent" liftIO $ getNotification conn dbSource conn ver _ -> do let ver' = maximum $ map fst8 res CC.yieldMany res dbSource conn ver' dbSink :: MonadIO m => Connection -> C.ConduitT (Int, Int, Bool, UUID, Text, Value) C.Void m () dbSink conn = do evt <- C.await case evt of Nothing -> return () Just event -> do liftIO $ execute conn "INSERT INTO events \ \(srv_id, stream_id, cmd, cmd_id, correlation_id, event_data) \ \VALUES (?, ?, ?, ?, ?, ?)" event liftIO $ execute_ conn "NOTIFY MyEvent" dbSink conn
Footnotes:
If I've missed something crucial I would of course love to hear about it.
Choosing a conduit randomly
Lately I've been playing around conduit. One thing I wanted to try out was to set up processing where one processing step was chosen on random from a number of components, based on weights. In short I guess I wanted a function with a type something like this
foo :: [(Int, ConduitT i o m r)] -> ConduitT i o m r
I have to admit I don't even know where to start writing such a function1 but after a little bit of thinking I realised I could get the same effect by controlling how chunks of data is routed. That is, instead of choosing a component randomly, I can choose a route randomly. It would look something like when choosing from three components
+---------+ +----------+ +-------------+
| Filter | | Drop tag | | Component A |
+-->| Value-0 |-->| |-->| |--+
| +---------+ +----------+ +-------------+ |
+----------------+ | +---------+ +----------+ +-------------+ |
| Choose random | | | Filter | | Drop tag | | Component B | |
| value based on +----->| Value-1 |-->| |-->| |----->
| weights | | +---------+ +----------+ +-------------+ |
+----------------+ | +---------+ +----------+ +-------------+ |
| | Filter | | Drop tag | | Component C | |
+-->| Value-2 |-->| |-->| |--+
+---------+ +----------+ +-------------+
That is
- For each chunk that comes in, choose a value randomly based on weights and tag the chunk with the choosen value, then
- split the processing into one route for each component,
- in each route filter out chunks tagged with a single value, and
- remove the tag, then
- pass the chunk to the component, and finally
- bring the routes back together again.
Out of these steps all but the very first one are already available in conduit:
- for splitting routes combining them again, use
sequenceConduits - for filtering, use
filter - for dropping the tag, use
map
What's left is the beginning. I started with a function to pick a value on random based on weights2
pickByWeight :: [(Int, b)] -> IO b pickByWeight xs = randomRIO (1, tot) >>= \ n -> return (pick n xs) where tot = sum $ map fst xs pick n ((k, x):xs) | n <= k = x | otherwise = pick (n - k) xs pick _ _ = error "pick error"
Using that I then made a component that tags chunks
picker ws = do evt <- await case evt of Nothing -> return () Just e -> do p <- liftIO $ pickByWeight ws yield (p, e) picker ws
I was rather happy with this…
@snoyberg just have to let you know, conduit is a joy to use. Thanks for sharing it.
– Magnus Therning (@magthe) February 6, 2019
Footnotes:
Using stack to get around upstream bugs
Recently I bumped into a bug in amazonka.1 I can't really sit around waiting for Amazon to fix it, and then for amazonka to use the fixed documentation to generate the code and make another release.
Luckily stack contains features that make it fairly simple to work around this
bug until it's properly fixed. Here's how.
- Put the upstream code in a git repository of your own. In my case I simply forked the amazonka repository on github (my fork is here).
- Fix the bug and commit the change. My change to amazonka-codepipeline was simply to remove the missing fields – it was easier than trying to make them optional (i.e. wrapping them in =Maybe=s).
- Tell
slackto use the code from your modified git repository. In my case I added the following to myslack.yaml:
extra-deps:
- github: magthe/amazonka
commit: 1543b65e3a8b692aa9038ada68aaed9967752983
subdirs:
- amazonka-codepipeline
That's it!
Footnotes:
The guilty party is Amazon, not amazonka, though I was a little surprised that there doesn't seem to be any established way to modify the Amazon API documentation before it's used to autogenerate the Haskell code.
The ReaderT design pattern or tagless final?
The other week I read V. Kevroletin's Introduction to Tagless Final and realised that a couple of my projects, both at work and at home, would benefit from a refactoring to that approach. All in all I was happy with the changes I made, even though I haven't made use of all the way. In particular there I could further improve the tests in a few places by adding more typeclasses. For now it's good enough and I've clearly gotten some value out of it.
I found mr. Kevroletin's article to be a good introduction so I've been passing it on when people on the Functional programming slack bring up questions about how to organize their code as applications grow. In particular if they mention that they're using monad transformers. I did exactly that just the other day @solomon wrote
so i've created a rats nest of IO where almost all the functions in my program are in
ReaderT Env IO ()and I'm not sure how to purify everything and move the IO to the edge of the program
I proposed tagless final and passed the URL on, and then I got a pointer to the article The ReaderT Design Patter which I hadn't seen before.
The two approches are similar, at least to me, and I can't really judge if one's
better than the other. Just to get a feel for it I thought I'd try to rewrite
the example in the ReaderT article in a tagless final style.
A slightly changed example of ReaderT design pattern
I decided to make a few changes to the example in the article:
- I removed the
modifyfunction, instead the code uses the typeclass functionmodifyBalancedirectly. - I separated the instances needed for the tests spatially in the code just to make it easier to see what's "production" code and what's test code.
- I combined the
mainfunctions from the various examples to that both an example (main0) and the test (main1) are run. - I switched from
Control.Concurrent.Async.Lifted.Safe(frommonad-control) toUnliftIO.Async(fromunliftio)
After that the code looks like this
{-# LANGUAGE FlexibleContexts #-} {-# LANGUAGE FlexibleInstances #-} import Control.Concurrent.STM import Control.Monad.Reader import qualified Control.Monad.State.Strict as State import Say import Test.Hspec import UnliftIO.Async data Env = Env { envLog :: !(String -> IO ()) , envBalance :: !(TVar Int) } class HasLog a where getLog :: a -> (String -> IO ()) instance HasLog Env where getLog = envLog class HasBalance a where getBalance :: a -> TVar Int instance HasBalance Env where getBalance = envBalance class Monad m => MonadBalance m where modifyBalance :: (Int -> Int) -> m () instance (HasBalance env, MonadIO m) => MonadBalance (ReaderT env m) where modifyBalance f = do env <- ask liftIO $ atomically $ modifyTVar' (getBalance env) f logSomething :: (MonadReader env m, HasLog env, MonadIO m) => String -> m () logSomething msg = do env <- ask liftIO $ getLog env msg main0 :: IO () main0 = do ref <- newTVarIO 4 let env = Env { envLog = sayString , envBalance = ref } runReaderT (concurrently_ (modifyBalance (+ 1)) (logSomething "Increasing account balance")) env balance <- readTVarIO ref sayString $ "Final balance: " ++ show balance instance HasLog (String -> IO ()) where getLog = id instance HasBalance (TVar Int) where getBalance = id instance Monad m => MonadBalance (State.StateT Int m) where modifyBalance = State.modify main1 :: IO () main1 = hspec $ do describe "modify" $ do it "works, IO" $ do var <- newTVarIO (1 :: Int) runReaderT (modifyBalance (+ 2)) var res <- readTVarIO var res `shouldBe` 3 it "works, pure" $ do let res = State.execState (modifyBalance (+ 2)) (1 :: Int) res `shouldBe` 3 describe "logSomething" $ it "works" $ do var <- newTVarIO "" let logFunc msg = atomically $ modifyTVar var (++ msg) msg1 = "Hello " msg2 = "World\n" runReaderT (logSomething msg1 >> logSomething msg2) logFunc res <- readTVarIO var res `shouldBe` (msg1 ++ msg2) main :: IO () main = main0 >> main1
I think the distinguising features are
- The application environmant,
Envwill contain configuraiton values (not in this example), state,envBalance, and functions we might want to vary,envLog - There is no explicit type representing the execution context
- Typeclasses are used to abstract over application environment,
HasLogandHasBalance - Typeclasses are used to abstract over operations,
MonadBalance - Typeclasses are implemented for both the application environment,
HasLogandHasBalance, and the execution context,MonadBalance
In the end this makes for code with very loose couplings; there's not really any
single concrete type that implements all the constraints to work in the "real"
main function (main0). I could of course introduce a type synonym for it
type App = ReaderT Env IO
but it brings no value – it wouldn't be used explicitly anywhere.
A tagless final version
In order to compare the ReaderT design pattern to tagless final (as I
understand it) I made an attempt to translate the code above. The code below is
the result.1
{-# LANGUAGE FlexibleContexts #-} {-# LANGUAGE FlexibleInstances #-} {-# LANGUAGE GeneralizedNewtypeDeriving #-} {-# LANGUAGE MultiParamTypeClasses #-} {-# LANGUAGE TypeFamilies #-} import Control.Concurrent.STM import qualified Control.Monad.Identity as Id import Control.Monad.Reader import qualified Control.Monad.State.Strict as State import Say import Test.Hspec import UnliftIO (MonadUnliftIO) import UnliftIO.Async newtype Env = Env {envBalance :: TVar Int} newtype AppM a = AppM {unAppM :: ReaderT Env IO a} deriving (Functor, Applicative, Monad, MonadIO, MonadReader Env, MonadUnliftIO) runAppM :: Env -> AppM a -> IO a runAppM env app = runReaderT (unAppM app) env class Monad m => ModifyM m where mModify :: (Int -> Int) -> m () class Monad m => LogSomethingM m where mLogSomething :: String -> m() instance ModifyM AppM where mModify f = do ref <- asks envBalance liftIO $ atomically $ modifyTVar' ref f instance LogSomethingM AppM where mLogSomething = liftIO . sayString main0 :: IO () main0 = do ref <- newTVarIO 4 let env = Env ref runAppM env (concurrently_ (mModify (+ 1)) (mLogSomething "Increasing account balance")) balance <- readTVarIO ref sayString $ "Final balance: " ++ show balance newtype ModifyAppM a = ModifyAppM {unModifyAppM :: State.StateT Int Id.Identity a} deriving (Functor, Applicative, Monad, State.MonadState Int) runModifyAppM :: Int -> ModifyAppM a -> (a, Int) runModifyAppM s app = Id.runIdentity $ State.runStateT (unModifyAppM app) s instance ModifyM ModifyAppM where mModify = State.modify' newtype LogAppM a = LogAppM {unLogAppM :: ReaderT (TVar String) IO a} deriving (Functor, Applicative, Monad, MonadIO, MonadReader (TVar String)) runLogAppM :: TVar String -> LogAppM a -> IO a runLogAppM env app = runReaderT (unLogAppM app) env instance LogSomethingM LogAppM where mLogSomething msg = do var <- ask liftIO $ atomically $ modifyTVar var (++ msg) main1 :: IO () main1 = hspec $ do describe "mModify" $ do it "works, IO" $ do var <- newTVarIO 1 runAppM (Env var) (mModify (+ 2)) res <- readTVarIO var res `shouldBe` 3 it "works, pure" $ do let (_, res) = runModifyAppM 1 (mModify (+ 2)) res `shouldBe` 3 describe "mLogSomething" $ it "works" $ do var <- newTVarIO "" runLogAppM var (mLogSomething "Hello" >> mLogSomething "World!") res <- readTVarIO var res `shouldBe` "HelloWorld!" main :: IO () main = main0 >> main1
The steps for the "real" part of the program were
- Introduce an execution type,
AppM, with a convenience function for running it,runAppM - Remove the log function from the environment type,
envLoginEnv - Remove all the
HasXclasses - Create a new operations typeclass for logging,
LogSomethingM - Rename the operations typeclass for modifying the balance to match the naming
found in the tagless article a bit better,
ModifyM - Implement instances of both operations typeclasses for
AppM
For testing the steps were
- Define an execution type for each test,
ModifyAppMandLogAppM, with some convenience functions for running them,runModifyAppMandrunLogAppM - Write instances for the operations typeclasses, one for each
So I think the distinguising features are
- There's both an environment type,
Env, and an execution typeAppMthat wraps it - The environment holds only configuration values (none in this example), and
state (
envBalance) - Typeclasses are used to abstract over operations,
LogSomethingMandModifyM - Typeclasses are only implemented for the execution type
This version has slightly more coupling, the execution type specifies the environment to use, and the operations are tied directly to the execution type. However, this coupling doesn't really make a big difference – looking at the pure modify test the amount of code don't differ by much.
A short note (mostly to myself)
I did write it using monad-control first, and then I needed an instance for
MonadBaseControl IO. Deriving it automatically requires UndecidableInstances
and I didn't really dare turn that on, so I ended up writing the instance. After
some help on haskell-cafe it ended up looking like this
instance MonadBaseControl IO AppM where type StM AppM a = a liftBaseWith f = AppM (liftBaseWith $ \ run -> f (run . unAppM)) restoreM = return
Conclusion
My theoretical knowledge isn't anywhere near good enough to say anything
objectively about the difference in expressiveness of the two design patterns.
That means that my conclusion comes down to taste, do you like the readerT
patter or tagless final better?
I like the slightly looser coupling I get with the ReaderT pattern. Loose
coupling is (almost) always a desirable goal. However, I can see that tying the
typeclass instances directly to a concrete execution type results in the intent
being communicated a little more clearly. Clearly communicating intent in code
is also a desirable goal. In particular I suspect it'll result in more
actionable error messages when making changes to the code – the error will tell
me that my execution type lacks an instance of a specific typeclass, instead of
it telling me that a particular transformer stack does. On the other hand, in
the ReaderT pattern that stack is very shallow.
One possibility would be that one pattern is better suited for libraries and the other for applications. I don't think that's the case though as in both cases the library code would be written in a style that results in typeclass constraints on the caller and providing instances for those typeclasses is roughly an equal amount of work for both styles.
Footnotes:
Please do point out any mistakes I've made in this, in particular if they stem from me misunderstanding tagless final completely.
A missing piece in my Emacs/Spacemacs setup for Haskell development
With the help of a work mate I've finally found this gem that's been missing from my Spacemacs setup
(with-eval-after-load 'intero (flycheck-add-next-checker 'intero '(warning . haskell-hlint)) (flycheck-add-next-checker 'intero '(warning . haskell-stack-ghc)))
Tagless final and Scotty
For a little while I've been playing around with event sourcing in Haskell using
Conduit and Scotty. I've come far enough that the basic functionality I'm
after is there together with all those little bits that make it a piece of
software that's fit for deployment in production (configuration, logging, etc.).
There's just one thing that's been nagging me, testability.
The app is built of two main parts, a web server (Scotty) and a pipeline of
stream processing components (Conduit). The part using Scotty is utilising a
simple monad stack, ReaderT Config IO, and the Conduit part is using
Conduit In Out IO. This means that in both parts the outer edge, the part
dealing with the outside world, is running in IO directly. Something that
isn't really aiding in testing.
I started out thinking that I'd rewrite what I have using a free monad with a
bunch of interpreters. Then I remembered that I have "check out tagless final".
This post is a record of the small experiments I did to see how to use it with
Scotty to achieve (and actually improve) on the code I have in my
production-ready code.
1 - Use tagless final with Scotty
As a first simple little experiment I wrote a tiny little web server that would
print a string to stdout when receiving the request to GET /route0.
The printing to stdout is the operation I want to make abstract.
class Monad m => MonadPrinter m where mPutStrLn :: Text -> m ()
I then created an application type that is an instance of that class.
newtype AppM a = AppM { unAppM :: IO a } deriving (Functor, Applicative, Monad, MonadIO) instance MonadPrinter AppM where mPutStrLn t = liftIO $ putStrLn (unpack t)
Then I added a bit of Scotty boilerplate. It's not strictly necessary, but
does make the code a bit nicer to read.
type FooM = ScottyT Text AppM type FooActionM = ActionT Text AppM foo :: MonadIO m => Port -> ScottyT Text AppM () -> m () foo port = scottyT port unAppM
With that in place the web server itself is just a matter of tying it all together.
main :: IO () main = do foo 3000 $ do get "/route0" $ do lift $ mPutStrLn "getting /route0" json $ object ["route0" .= ("ok" :: String)] notFound $ json $ object ["error" .= ("not found" :: String)]
That was simple enough.
2 - Add configuration
In order to try out how to deal with configuration I added a class for doing some simple logging
class Monad m => MonadLogger m where mLog :: Text -> m ()
The straight forward way to deal with configuration is to create a monad stack
with ReaderT and since it's logging I want to do the configuration consists of
a single LoggerSet (from fast-logger).
newtype AppM a = AppM { unAppM :: ReaderT LoggerSet IO a } deriving (Functor, Applicative, Monad, MonadIO, MonadReader LoggerSet)
That means the class instance can be implemented like this
instance MonadLogger AppM where mLog msg = do ls <- ask liftIO $ pushLogStrLn ls $ toLogStr msg
Of course foo has to be changed too, and it becomes a little easier with a
wrapper for runReaderT and unAppM.
foo :: MonadIO m => LoggerSet -> Port -> ScottyT Text AppM () -> m () foo ls port = scottyT port (`runAppM` ls) runAppM :: AppM a -> LoggerSet -> IO a runAppM app ls = runReaderT (unAppM app) ls
With that in place the printing to stdout can be replaced by a writing to the
log.
main :: IO () main = do ls <- newStdoutLoggerSet defaultBufSize foo ls 3000 $ do get "/route0" $ do lift $ mLog "log: getting /route0" json $ object ["route0" .= ("ok" :: String)] notFound $ json $ object ["error" .= ("not found" :: String)]
Not really a big change, I'd say. Extending the configuration is clearly straight forward too.
3 - Per-request configuration
At work we use correlation IDs1 and I think that the most convenient way to
deal with it is to put the correlation ID into the configuration after
extracting it. That is, I want to modify the configuration on each request.
Luckily it turns out to be possible to do that, despite using ReaderT for
holding the configuration.
I can't be bothered with a full implementation of correlation ID for this little
experiment, but as long as I can get a new AppM by running a function on the
configuration it's just a matter of extracting the correct header from the
request. For this experiment it'll do to just modify an integer in the
configuration.
I start with defining a type for the configuration and changing AppM.
type Config = (LoggerSet, Int) newtype AppM a = AppM { unAppM :: ReaderT Config IO a } deriving (Functor, Applicative, Monad, MonadIO, MonadReader Config)
The logger instance has to be changed accordingly of course.
instance MonadLogger AppM where mLog msg = do (ls, i) <- ask liftIO $ pushLogStrLn ls $ toLogStr msg <> toLogStr (":" :: String) <> toLogStr (show i)
The get function that comes with scotty isn't going to cut it, since it has
no way of modifying the configuration, so I'll need a new one.
mGet :: ScottyError e => RoutePattern -> ActionT e AppM () -> ScottyT e AppM () mGet p a = get p $ do withCfg (\ (ls, i) -> (ls, succ i)) a
The tricky bit is in the withCfg function. It's indeed not very easy to read,
I think
withCfg = mapActionT . withAppM where mapActionT f (ActionT a) = ActionT $ (mapExceptT . mapReaderT . mapStateT) f a withAppM f a = AppM $ withReaderT f (unAppM a)
Basically it reaches into the guts of scotty's ActionT type (the details are
exposed in Web.Scotty.Internal.Types, thanks for not hiding it completely),
and modifies the ReaderT Config I've supplied.
The new server has two routes, the original one and a new one at GET /route1.
main :: IO () main = do putStrLn "Starting" ls <- newStdoutLoggerSet defaultBufSize foo (ls, 0) 3000 $ do get "/route0" $ do lift $ mLog "log: getting /route0" json $ object ["route0" .= ("ok" :: String)] mGet "/route1" $ do lift $ mLog "log: getting /route1" json $ object ["route1" .= ("bar" :: String)] notFound $ json $ object ["error" .= ("not found" :: String)]
It's now easy to verify that the original route, GET /route0, logs a string
containing the integer '0', while the new route, GET /route1, logs a string
containing the integer '1'.
Footnotes:
If you don't know what it is you'll find multiple sources by searching for "http correlation-id". A consistent approach to track correlation IDs through microservices is as good a place to start as any.
Zipping streams
Writing the following is easy after glancing through the documentation for conduit:
foo = let src = mapM_ C.yield [0..9 :: Int] p0 = CC.map (\ i -> ("p0", succ i)) p1 = CC.filter odd .| CC.map (\ i -> ("p1", i)) p = C.getZipConduit $ C.ZipConduit p0 <* C.ZipConduit p1 sink = CC.mapM_ print in C.runConduit $ src .| p .| sink
Neither pipes nor streaming make it as easy to figure out. I must be missing something! What functions should I be looking at?
Using a configuration in Scotty
At work we're only now getting around to put correlation IDs into use. We write most our code in Clojure but since I'd really like to use more Haskell at work I thought I'd dive into Scotty and see how to deal with logging and then especially how to get correlation IDs into the logs.
The types
For configuration it decided to use the reader monad inside ActionT from
Scotty. Enter Chell:
type ChellM c = ScottyT Text (ReaderT c IO) type ChellActionM c = ActionT Text (ReaderT c IO)
In order to run it I wrote a function corresponding to scotty:
chell :: c -> Port -> ChellM () -> IO () chell cfg port a = scottyOptsT opts (flip runReaderT cfg) a where opts = def { verbose = 0 , settings = (settings def) { settingsPort = port } }
Correlation ID
To deal with the correlation ID each incoming request should be checked for the
HTTP header X-Correlation-Id and if present it should be used during logging.
If no such header is present then a new correlation ID should be created. Since
it's per request it feels natural to create a WAI middleware for this.
The easiest way I could come up with was to push the correlation ID into the request's headers before it's passed on:
requestHeaderCorrelationId :: Request -> Maybe ByteString requestHeaderCorrelationId = lookup "X-Correlation-Id" . requestHeaders correlationId :: Middleware correlationId app req sendResponse = do u <- (randomIO :: IO UUID) let corrId = maybe (toASCIIBytes u) id (requestHeaderCorrelationId req) newHeaders = ("X-Correlation-Id", corrId) : (requestHeaders req) app (req { requestHeaders = newHeaders }) $ \ res -> sendResponse res
It also turns out to be useful to have both a default correlation ID and a function for pulling it out of the headers:
defaultCorrelationString :: ByteString defaultCorrelationString = "no-correlation-id" getCorrelationId :: Request -> ByteString getCorrelationId r = maybe defaultCorrelationString id (requestHeaderCorrelationId r)
Getting the correlation ID into the configuration
Since the correlation ID should be picked out of the request on handling of
every request it's useful to have it the configuration when running the
ChellActionM actions. However, since the correlation ID isn't available when
running the reader (the call to runReaderT in chell) something else is
called for. When looking around I found local (and later I was pointed to the
more general withReaderT) but it doesn't have a suitable type. After some help
on Twitter I arrived at withConfig which allows me to run an action in a
modified configuration:
withConfig :: (c -> c') -> ChellActionM c' () -> ChellActionM c () withConfig = mapActionT . withReaderT where mapActionT f (ActionT a) = ActionT $ (mapExceptT . mapReaderT . mapStateT) f a
Making it handy to use
Armed with this I can put together some functions to replace Scotty's get,
post, etc. With a configuration type like this:
data Config = Cfg LoggerSet ByteString
The modified get looks like this (Scotty's original is S.get)
get :: RoutePattern -> ChellActionM Config () -> ChellM Config () get p a = S.get p $ do r <- request let corrId = getCorrelationId r withConfig (\ (Cfg l _) -> Cfg l corrId) a
With this in place I can use the simpler ReaderT Config IO for inner functions
that need to log.
QuickCheck on a REST API
Since I'm working with web stuff nowadays I thought I'd play a little with translating my old post on using QuickCheck to test C APIs to the web.
The goal and how to reach it
I want to use QuickCheck to test a REST API, just like in the case of the C API the idea is to
- generate a sequence of API calls (a program), then
- run the sequence against a model, as well as
- run the sequence against the web service, and finally
- compare the resulting model against reality.
The REST API
I'll use a small web service I'm working on, and then concentrate on only a small part of the API to begin with.
The parts of the API I'll use for the programs at this stage are
| Method | Route | Example in | Example out |
|---|---|---|---|
POST |
/users |
{"userId": 0, "userName": "Yogi Berra"} |
{"userId": 42, "userName": "Yogi Berra"} |
DELETE |
/users/:id |
The following API calls will also be used, but not in the programs
| Method | Route | Example in | Example out |
|---|---|---|---|
GET |
/users |
[0,3,7] |
|
GET |
/users/:id |
{"userId": 42, "userName": "Yogi Berra"} |
|
POST |
/reset |
Representing API calls
Given the information about the API above it seems the following is enough to represent the two calls of interest together with a constructor representing the end of a program
data ApiCall = AddUser Text | DeleteUser Int | EndProgram deriving (Show)
and a program is just a sequence of calls, so list of ApiCall will do.
However, since I want to generate sequences of calls, i.e. implement
Arbitrary, I'll wrap it in a newtype
newtype Program = Prog [ApiCall]
Running against a model (simulation)
First of all I need to decide what model to use. Based on the part of the API
I'm using I'll use an ordinary dictionary of Int and Text
type Model = M.Map Int Text
Simulating execution of a program is simulating each call against a model that's updated with each step. I expect the final model to correspond to the state of the real service after the program is run for real. The simulation begins with an empty dictionary.
simulateProgram :: Program -> Model simulateProgram (Prog cs) = foldl simulateCall M.empty cs
The simulation of the API calls must then be a function taking a model and a call, returning an updated model
simulateCall :: Model -> ApiCall -> Model simulateCall m (AddUser t) = M.insert k t m where k = succ $ foldl max 0 (M.keys m) simulateCall m (DeleteUser k) = M.delete k m simulateCall m EndProgram = m
Here I have to make a few assumptions. First, I assume the indeces for the users
start on 1. Second, that the next index used always is the successor of
highest currently used index. We'll see how well this holds up to reality later
on.
Running against the web service
Running the program against the actual web service follows the same pattern, but
here I'm dealing with the real world, so it's a little more messy, i.e. IO is
involved. First the running of a single call
runCall :: Manager -> ApiCall -> IO () runCall mgr (AddUser t) = do ireq <- parseRequest "POST http://localhost:3000/users" let req = ireq { requestBody = RequestBodyLBS (encode $ User 0 t)} resp <- httpLbs req mgr guard (status201 == responseStatus resp) runCall mgr (DeleteUser k) = do req <- parseRequest $ "DELETE http://localhost:3000/users/" ++ show k resp <- httpNoBody req mgr guard (status200 == responseStatus resp) runCall _ EndProgram = return ()
The running of a program is slightly more involved. Of course I have to set up
the Manager needed for the HTTP calls, but I also need to
- ensure that the web service is in a well-known state before starting, and
- extract the state of the web service after running the program, so I can compare it to the model
runProgram :: Program -> IO Model runProgram (Prog cs) = do mgr <- newManager defaultManagerSettings resetReq <- parseRequest "POST http://localhost:3000/reset" httpNoBody resetReq mgr mapM_ (runCall mgr) cs model <- extractModel mgr return model
The call to POST /reset resets the web service. I would have liked to simply
restart the service completely, but I failed in automating it. I think I'll have
to take a closer look at the implementation of scotty to find a way.
Extracting the web service state and packaging it in a Model is a matter of
calling GET /users and then repeatedly calling GET /users/:id with each id
gotten from the first call
extractModel :: Manager -> IO Model extractModel mgr = do req <- parseRequest "http://localhost:3000/users" resp <- httpLbs req mgr let (Just ids) = decode (responseBody resp) :: Maybe [Int] users <- forM ids $ \ id -> do req <- parseRequest $ "http://localhost:3000/users/" ++ show id resp <- httpLbs req mgr let (Just (user:_)) = decode (responseBody resp) :: Maybe [User] return user return $ foldl (\ map (User id name) -> M.insert id name map) M.empty users
Generating programs
My approach to generating a program is based on the idea that given a certain
state there is only a limited number of possible calls that make sense. Given a
model m it makes sense to make one of the following calls:
- add a new user
- delete an existing user
- end the program
Based on this writing genProgram is rather straight forward
genProgram :: Gen Program genProgram = Prog <$> go M.empty where possibleAddUser _ = [AddUser <$> arbitrary] possibleDeleteUser m = map (return . DeleteUser) (M.keys m) possibleEndProgram _ = [return EndProgram] go m = do let possibles = possibleDeleteUser m ++ possibleAddUser m ++ possibleEndProgram m s <- oneof possibles let m' = simulateCall m s case s of EndProgram -> return [] _ -> (s:) <$> go m'
Armed with that the Arbitrary instance for Program can be implemented as1
instance Arbitrary Program where arbitrary = genProgram shrink p = []
The property of an API
The steps in the first section can be used as a recipe for writing the property
prop_progCorrectness :: Program -> Property prop_progCorrectness program = monadicIO $ do let simulatedModel = simulateProgram program runModel <- run $ runProgram program assert $ simulatedModel == runModel
What next?
There are some improvements that I'd like to make:
- Make the generation of
Programbetter in the sense that the programs become longer. I think this is important as I start tackling larger APIs. - Write an implementation of
shrinkforProgram. With longer programs it's of course more important to actually implementshrink.
I'd love to hear if others are using QuickCheck to test REST APIs in some way,
if anyone has suggestions for improvements, and of course ideas for how to
implement shrink in a nice way.
Footnotes:
Yes, I completely skip the issue of shrinking programs at this point. This is OK at this point though, because the generated =Programs=s do end up to be very short indeed.
Using QuickCheck to test C APIs
Last year at ICFP I attended the tutorial on QuickCheck with John Hughes. We got to use the Erlang implementation of QuickCheck to test a C API. Ever since I've been planning to do the same thing using Haskell. I've put it off for the better part of a year now, but then Francesco Mazzoli wrote about inline-c (Call C functions from Haskell without bindings and I found the motivation to actually start writing some code.
The general idea
Many C APIs are rather stateful beasts so to test it I
- generate a sequence of API calls (a program of sorts),
- run the sequence against a model,
- run the sequence against the real implementation, and
- compare the model against the real state each step of the way.
The C API
To begin with I hacked up a simple implementation of a stack in C. The "specification" is
/** * Create a stack. */ void *create(); /** * Push a value onto an existing stack. */ void push (void *, int); /** * Pop a value off an existing stack. */ int pop(void *);
Using inline-c to create bindings for it is amazingly simple:
{-# LANGUAGE QuasiQuotes #-} {-# LANGUAGE TemplateHaskell #-} module CApi where import qualified Language.C.Inline as C import Foreign.Ptr C.include "stack.h" create :: IO (Ptr ()) create = [C.exp| void * { create() } |] push :: Ptr () -> C.CInt -> IO () push s i = [C.exp| void { push($(void *s), $(int i)) } |] pop :: Ptr () -> IO C.CInt pop s = [C.exp| int { pop($(void *s)) } |]
In the code below I import this module qualified.
Representing a program
To represent a sequence of calls I first used a custom type, but later realised that there really was no reason at all to not use a wrapped list:
newtype Program a = P [a] deriving (Eq, Foldable, Functor, Show, Traversable)
Then each of the C API functions can be represented with
data Statement = Create | Push Int | Pop deriving (Eq, Show)
Arbitrary for Statement
My implementation of Arbitrary for Statement is very simple:
instance Arbitrary Statement where arbitrary = oneof [return Create, return Pop, liftM Push arbitrary] shrink (Push i) = Push <$> shrink i shrink _ = []
That is, arbitrary just returns one of the constructors of Statement, and
shrinking only returns anything for the one constructor that takes an argument,
Push.
Prerequisites of Arbitrary for Program Statement
I want to ensure that all Program Statement are valid, which means I need to
define the model for running the program and functions for checking the
precondition of a statement as well as for updating the model (i.e. for running
the Statement).
Based on the C API above it seems necessary to track creation, the contents of
the stack, and even if it isn't explicitly mentioned it's probably a good idea
to track the popped value. Using record (Record is imported as R, and
Record.Lens as RL) I defined it like this:
type ModelContext = [R.r| { created :: Bool, pop :: Maybe Int, stack :: [Int] } |]
Based on the rather informal specification I coded the pre-conditions for the three statements as
preCond :: ModelContext -> Statement -> Bool preCond ctx Create = not $ RL.view [R.l| created |] ctx preCond ctx (Push _) = RL.view [R.l| created |] ctx preCond ctx Pop = RL.view [R.l| created |] ctx
That is
Createrequires that the stack hasn't been created already.Push irequires that the stack has been created.Popalso requires that the stack has been created.
Furthermore the "specification" suggests the following definition of a function for running a statement:
modelRunStatement :: ModelContext -> Statement -> ModelContext modelRunStatement ctx Create = RL.set [R.l| created |] True ctx modelRunStatement ctx (Push i) = RL.over [R.l| stack |] (i :) ctx modelRunStatement ctx Pop = [R.r| { created = c, pop = headMay s, stack = tail s } |] where c = RL.view [R.l| created |] ctx s = RL.view [R.l| stack |] ctx
(This definition assumes that the model satisfies the pre-conditions, as can be
seen in the use of tail.)
Arbitrary for Program Statement
With this in place I can define Arbitrary for Program Statement as
follows.
instance Arbitrary (Program Statement) where arbitrary = liftM P $ ar baseModelCtx where ar m = do push <- liftM Push arbitrary let possible = filter (preCond m) [Create, Pop, push] if null possible then return [] else do s <- oneof (map return possible) let m' = modelRunStatement m s frequency [(499, liftM2 (:) (return s) (ar m')), (1, return [])]
The idea is to, in each step, choose a valid statement given the provided model
and cons it with the result of a recursive call with an updated model. The
constant 499 is just an arbitrary one I chose after running arbitrary a few
times to see how long the generated programs were.
For shrinking I take advantage of the already existing implementation for lists:
shrink (P p) = filter allowed $ map P (shrink p) where allowed = and . snd . mapAccumL go baseModelCtx where go ctx s = (modelRunStatement ctx s, preCond ctx s)
Some thoughts so far
I would love making an implementation of Arbitrary s, where s is something
that implements a type class that contains preCond, modelRunStatement and
anything else needed. I made an attempt using something like
class S a where type Ctx a :: * baseCtx :: Ctx a preCond :: Ctx a -> a -> Bool ...
However, when trying to use baseCtx in an implementation of arbitrary I ran
into the issue of injectivity. I'm still not entirely sure what that means, or
if there is something I can do to work around it. Hopefully someone reading this
can offer a solution.
Running the C code
When running the sequence of Statement against the C code I catch the results
in
type RealContext = [r| { o :: Ptr (), pop :: Maybe Int } |]
Actually running a statement and capturing the output in a RealContext is
easily done using inline-c and record:
realRunStatement :: RealContext -> Statement -> IO RealContext realRunStatement ctx Create = CApi.create >>= \ ptr -> return $ RL.set [R.l| o |] ptr ctx realRunStatement ctx (Push i) = CApi.push o (toEnum i) >> return ctx where o = RL.view [R.l| o |] ctx realRunStatement ctx Pop = CApi.pop o >>= \ v -> return $ RL.set [R.l| pop |] (Just (fromEnum v)) ctx where o = RL.view [R.l| o |] ctx
Comparing states
Comparing a ModelContext and a RealContext is easily done:
compCtx :: ModelContext -> RealContext -> Bool compCtx mc rc = mcC == rcC && mcP == rcP where mcC = RL.view [R.l| created |] mc rcC = RL.view [R.l| o |] rc /= nullPtr mcP = RL.view [R.l| pop|] mc rcP = RL.view [R.l| pop|] rc
Verifying a Program Statement
With all that in place I can finally write a function for checking the validity of a program:
validProgram :: Program Statement -> IO Bool validProgram p = and <$> snd <$> mapAccumM go (baseModelCtx, baseRealContext) p where runSingleStatement mc rc s = realRunStatement rc s >>= \ rc' -> return (modelRunStatement mc s, rc') go (mc, rc) s = do ctxs@(mc', rc') <- runSingleStatement mc rc s return (ctxs, compCtx mc' rc')
(This uses mapAccumM from an earlier post of mine.)
The property, finally!
To wrap this all up I then define the property
prop_program :: Program Statement -> Property prop_program p = monadicIO $ run (validProgram p) >>= assert
and a main function
main :: IO () main = quickCheck prop_program
Edit 2015-07-17: Adjusted the description of the pre-conditions to match the code.
mapAccum in monad
I recently had two functions of very similar shape, only difference was that one
was pure and the other need some I/O. The former was easily written using
mapAccumL. I failed to find a function like mapAccumL that runs in a monad,
so I wrote up the following:
mapAccumM :: (Monad m, Traversable t) => (a -> b -> m (a, c)) -> a -> t b -> m (a, t c) mapAccumM f a l = swap <$> runStateT (mapM go l) a where go i = do s <- get (s', r) <- lift $ f s i put s' return r
Bring on the comments/suggestions/improvements/etc!
Adventures in parsing, part 4
I received a few comments on part 3 of this little mini-series and I just wanted
to address them. While doing this I still want the main functions of the parser
parseXxx to read like the maps file itself. That means I want to avoid
"reversing order" like thenChar and thenSpace did in part 2. I also don't
want to hide things, e.g. I don't want to introduce a function that turns (a <*
char ' ') <*> b into a <#> b.
So, first up is to do something about hexStr2Int <$> many1 hexDigit which
appears all over the place. I made it appear in even more places by moving
around a few parentheses; the following two functions are the same:
foo = a <$> (b <* c) bar = (a <$> b) <* c
Then I scrapped hexStr2Int completely and instead introduced hexStr:
hexStr = Prelude.read . ("0x" ++) <$> many1 hexDigit
This means that parseAddress can be rewritten to:
parseAddress = Address <$> hexStr <* char '-' <*> hexStr
Rather than, as Conal suggested, introduce an infix operation that addresses the
pattern (a <* char ' ') <*> b I decided to do something about a <* char c. I
feel Conal's suggestion, while shortening the code more than my solution, goes
against my wish to not hide things. This is the definition of <##>:
(<##>) l r = l <* char r
After this I rewrote parseAddress into:
parseAddress = Address <$> hexStr <##> '-' <*> hexStr
The pattern (== c) <$> anyChar appears three times in parsePerms so it got a
name and moved down into the where clause. I also modified cA to use pattern
matching. I haven't spent much time considering error handling in the parser, so
I didn't introduce a pattern matching everything else.
parsePerms = Perms <$> pP 'r' <*> pP 'w' <*> pP 'x' <*> (cA <$> anyChar) where pP c = (== c) <$> anyChar cA 'p' = Private cA 's' = Shared
The last change I did was remove a bunch of parentheses. I'm always a little hesitant removing parentheses and relying on precedence rules, I find I'm even more hesitant doing it when programming Haskell. Probably due to Haskell having a lot of infix operators that I'm unused to.
The rest of the parser now looks like this:
parseDevice = Device <$> hexStr <##> ':' <*> hexStr parseRegion = MemRegion <$> parseAddress <##> ' ' <*> parsePerms <##> ' ' <*> hexStr <##> ' ' <*> parseDevice <##> ' ' <*> (Prelude.read <$> many1 digit) <##> ' ' <*> (parsePath <|> string "") where parsePath = (many1 $ char ' ') *> (many1 anyChar)
I think these changes address most of the comments Conal and Twan made on the previous part. Where they don't I hope I've explained why I decided not to take their advice.
Comment by Jedaï:
That's really pretty ! Code you can read, but concise, Haskell is really good at that, though I need to look at how Applicative works its magic. :)
Good work !
Comment by Conal Elliot:
Magnus wrote
I also don’t want to hide things, e.g. I don’t want to introduce a function that turns
(a <* char ' ') <*> bintoa <#> b.
I'm puzzled about this comment. Aren't all of your definitions (as well as much of Parsec and other Haskell libraries) "hiding things"?
What appeals to me about a <#> b = (a <* char ' ') <*> b (and similarly for,
say "a <:> b", is that it captures the combination of a character separator
and <*>-style application. As your example illustrates (and hadn't previously
occurred to me), this combination is very common.
Response to Conal:
Conal, you are right and I was unclear in what I meant. Basically I like the
idea of reading the parseXxx functions and see the structure of the original
maps file. At the moment I think that
parseAddress = Address <$> hexStr <##> '-' <*> hexStr
better reflects the structure of the maps file than hiding away the separator
inside an operator. I also find it doesn't require me to carry a lot of "mental
baggage" when reading the code (I suspect this is the thing that's been
bothering me with the love of introducing operators that seems so prevalent
among Haskell developers, thanks for helping me put a finger on it). However,
your persistence might be paying off ;-) I'm warming to the idea. I just have to
come up with a scheme for naming operators that allows easy reading of the code.
Comment by Conal Elliott:
Oh! I'm finally getting what you've meant about "hiding things" vs "reflect[ing]
the structure of the maps file". I think you want the separator characters to
show up in the parser, and between the sub-parsers that they separate.
Maybe what's missing in my <#> suggestion is that the choice of the space
character as a separator is far from obvious, and I guess that's what you're
saying about "mental baggage" naming the operators for easy reading.
I suppose you could use sepSpace and sepColon as operator names.
parseAddress = Address <$> hexStr `sepColon` hexStr parseRegion = MemRegion <$> parseAddress `sepSpace` parsePerms `sepSpace` ...
Still, an actual space/colon character would probably be clearer. For colon, you
could use <:>, but what for space?
Response to Conal:
Conal, that's exactly what I mean, just much more clearly expressed than I could ever hope to do.
I too was thinking of the problem with space in an operator…
Adventures in parsing, part 3
I got a great many comments, at least by my standards, on my earlier two posts
on parsing in Haskell. Especially on the latest one. Conal posted a comment on
the first pointing me towards liftM and its siblings, without telling me that
it would only be the first step towards "applicative style". So, here I go
again…
First off, importing Control.Applicative. Apparently <|> is defined in both
Applicative and in Parsec. I do use <|> from Parsec so preventing
importing it from Applicative seemed like a good idea:
import Control.Applicative hiding ( (<|>) )
Second, Cale pointed out that I need to make an instance for
Control.Applicative.Applicative for GenParser. He was nice enough to point
out how to do that, leaving syntax the only thing I had to struggle with:
instance Applicative (GenParser c st) where pure = return (<*>) = ap
I decided to take baby-steps and I started with parseAddress. Here's what it
used to look like:
parseAddress = let hexStr2Int = Prelude.read . ("0x" ++) in do start <- liftM hexStr2Int $ thenChar '-' $ many1 hexDigit end <- liftM hexStr2Int $ many1 hexDigit return $ Address start end
On Twan's suggestion I rewrote it using where rather than let ... in and
since this was my first function I decided to go via the ap function (at the
same time I broke out hexStr2Int since it's used in so many places):
parseAddress = do start <- return hexStr2Int `ap` (thenChar '-' $ many1 hexDigit) end <- return hexStr2Int `ap` (many1 hexDigit) return $ Address start end
Then on to applying some functions from Applicative:
parseAddress = Address start end
where
start = hexStr2Int <$> (thenChar '-' $ many1 hexDigit)
end = hexStr2Int <$> (many1 hexDigit)
By now the use of thenChar looks a little silly so I changed that part into
many1 hexDigit <* char '-' instead. Finally I removed the where part
altogether and use <*> to string it all together:
parseAddress = Address <$> (hexStr2Int <$> many1 hexDigit <* char '-') <*> (hexStr2Int <$> (many1 hexDigit))
From here on I skipped the intermediate steps and went straight for the last form. Here's what I ended up with:
parsePerms = Perms <$> ( (== 'r') <$> anyChar) <*> ( (== 'w') <$> anyChar) <*> ( (== 'x') <$> anyChar) <*> (cA <$> anyChar) where cA a = case a of 'p' -> Private 's' -> Shared parseDevice = Device <$> (hexStr2Int <$> many1 hexDigit <* char ':') <*> (hexStr2Int <$> (many1 hexDigit)) parseRegion = MemRegion <$> (parseAddress <* char ' ') <*> (parsePerms <* char ' ') <*> (hexStr2Int <$> (many1 hexDigit <* char ' ')) <*> (parseDevice <* char ' ') <*> (Prelude.read <$> (many1 digit <* char ' ')) <*> (parsePath <|> string "") where parsePath = (many1 $ char ' ') *> (many1 anyChar)
I have to say I'm fairly pleased with this version of the parser. It reads about
as easy as the first version and there's none of the "reversing" that thenChar
introduced.
Comment by Conal Elliott:
A thing of beauty! I'm glad you stuck with it, Magnus.
Some much smaller points:
- The pattern
(== c) <$> anyChar(nicely written, btw) arises three times, so it might merit a name. - Similarly for
hexStr2Int <$> many1 hexDigit, especially when you rewritef <$> (a <* b)to(f <$> a) <* b. - The pattern
(a <* char ' ') <*> bcomes up a lot. How about naming it also, with a nice infix op, saya <#> b? - The cA definition could use pattern matching instead (e.g.,
cA 'p' = PrivateandcA 's' = Shared). - Some of your parens are unnecessary (3rd line of
parseDeviceand last ofparseRegion), since application binds more tightly than infix ops.
Comment by Twan van Laarhoven:
First of all, note that you don't need parentheses around parseSomething <*
char ' '.
You can also simplify things a bit more by combining hexStr2Int <$> many1
hexDigit into a function, then you could say:
parseHex = hexStr2Int <$> many1 hexDigit parseAddress = Address <$> parseHex <* char '-' <*> parseHex parseDevice = Device <$> parseHex <</em> char ':' <*> parseHex
Also, in cA, should there be a case for character other than 'p' or 's'?
Otherwise the program could fail with a pattern match error.
Response to Conal and Twan:
Conal and Twan, thanks for your suggestions. I'll put them into practice and post the "final" result as soon as I find some time.
More adventures in parsing
I received an interesting comment from Conal Elliott on my previous post on parsing I have to admit I wasn't sure I understood him at first, I'm still not sure I do, but I think I have an idea of what he means :-)
Basically my code is very sequential in that I use the do construct everywhere
in the parsing code. Personally I thought that makes the parser very easy to
read since the code very much mimics the structure of the maps file. I do
realise the code isn't very "functional" though so I thought I'd take Conal's
comments to heart and see what the result would be.
Let's start with observation that every entity in a line is separated by a space. However some things are separated by other characters. So the first thing I did was write a higher-order function that first reads something, then reads a character and returns the first thing that was read:
thenChar c f = f >>= (\ r -> char c >> return r)
Since space is used as a separator so often I added a short-cut for that:
thenSpace = thenChar ' '
Then I put that to use on parseAddress:
parseAddress = let hexStr2Int = Prelude.read . ("0x" ++) in do start <- thenChar '-' $ many1 hexDigit end <- many1 hexDigit return $ Address (hexStr2Int start) (hexStr2Int end)
Modifying the other parsing functions using =thenChar~ and thenSpace is
straight forward.
I'm not entirely sure I understand what Conal meant with the part about liftM
in his comment. I suspect his referring to the fact that I first read characters
and then convert them in the "constructors". By using liftM I can move the
conversion "up in the code". Here's parseAddress after I've moved the calls to
hexStr2Int:
parseAddress = let hexStr2Int = Prelude.read . ("0x" ++) in do start <- liftM hexStr2Int $ thenChar '-' $ many1 hexDigit end <- liftM hexStr2Int $ many1 hexDigit return $ Address start end
After modifying the other parsing functions in a similar way I ended up with this:
parsePerms = let cA a = case a of 'p' -> Private 's' -> Shared in do r <- liftM (== 'r') anyChar w <- liftM (== 'w') anyChar x <- liftM (== 'x') anyChar a <- liftM cA anyChar return $ Perms r w x a parseDevice = let hexStr2Int = Prelude.read . ("0x" ++) in do maj <- liftM hexStr2Int $ thenChar ':' $ many1 hexDigit min <- liftM hexStr2Int $ many1 hexDigit return $ Device maj min parseRegion = let hexStr2Int = Prelude.read . ("0x" ++) parsePath = (many1 $ char ' ') >> (many1 $ anyChar) in do addr <- thenSpace parseAddress perm <- thenSpace parsePerms offset <- liftM hexStr2Int $ thenSpace $ many1 hexDigit dev <- thenSpace parseDevice inode <- liftM Prelude.read $ thenSpace $ many1 digit path <- parsePath <|> string "" return $ MemRegion addr perm offset dev inode path
Is this code more "functional"? Is it easier to read? You'll have to be the judge of that…
Conal, if I got the intention of your comment completely wrong then feel free to tell me I'm an idiot ;-)
Comment by Holger:
Your story and Conal's comment inspired me to play around with liftM and I came up with this version of parseAddress:
parseAddress = let hexStr2Int = Prelude.read . ("0x" ++) in liftM3 (\ x _ y -> Address (hexStr2Int x) (hexStr2Int y)) (many1 hexDigit) (char '-') (many1 hexDigit)
You could probably rewrite all the functions in a similar way, but honestly I find your original code in do-notation much easier to read.
Response to Holger:
Yeah, the same line of thought made it a little difficult to fall asleep yesterday (yes, I know, nerdiness taken to new levels). My thoughts was something like this:
parseAddress = let hexStr2Int = ... in liftM2 Address (liftM hexStr2Int $ thenChar '-' $ many1 hexDigit) (liftM hexStr2Int $ many1 hexDigit)
I agree with you on readability. I also wonder if laziness could bite back or if `liftM2` guarantees an order of evaluation.
Comment by Holger:
I just looked at the source of liftM2/3 and it seems that it basically just resolves to an expression in do-notation. So it's just a shortcut and therefore should yield the same program.
Comment by Cale Gibbard:
liftM2 guarantees an ordering on the monadic computation, because it's defined like:
liftM2 f x y = do { u <- x; v <- y; return (f u v) }
Though, that's a little different from guaranteeing an order of evaluation – depending on the monad, the order of evaluation will vary. In any case, it shouldn't be much different from what you originally had.
Another thing you might like to play around with, at least in your head, is the fact that:
liftM2 f x y = return f `ap` x `ap` y liftM3 f x y z = return f `ap` x `ap` y `ap` z
and so on, which leads up to the style embodied by the Control.Applicative
library, though if you really want to play around with that, you'll need to
write a quick instance of Applicative for GenParser, which should just consist
of making pure = return and (<*>) = ap.
Comment by Twan van Laarhoven:
The best way to make parsing code readable is to use Data.Applicative. Also,
most people prefer where to let..in if possible. This gives something like:
parseHexStr = Prelude.read . ("0x" ++) many1 hexDigit parsePath = many1 (char ' ') *> many1 anyChar parseAddress = Address hexStr *> char '-' hexStr parseRegion = MemRegion parseAddress *> char ' ' parsePerms *> char ' ' parseHexStr *> char ' ' parseDevice *> char ' ' (Prelude.read many1 digit) *> char ' ' (parsePath return "")
Basicly (liftM# f x y z) can be written as f x <*> y <*> z.
Comment by Nick:
I find the thenSpace a bit difficult to read.I think something like this is
more natural, as it maintains the left-to-right relationship of the parsed data
and the following space:
aChar c r = char c >> return r aSpace = aChar ' ' ... do start <- many1 hexDigit >> aChar ....
note that I haven't tested this and my haskell-fu is not very strong, so I could be way off here.
Comment by Conal Elliot:
Yes, that's exactly the direction i had in mind. once you switch from "do" style to "liftM#" style, it's a simple step to replace the monad operators to applicative functor operators.
Response to Nick:
Nick, yes your way of writing it is easier to read. You'll need to change to
using >>= though:
do start <- many1 hexDigit >>= aChar '-'
Then you can mix in `liftM` as well:
do start <- liftM hexStr2Int $ many1 hexDigit >>= aChar '-'
to do the conversion. However, I think my initial version is even clearer:
do start <- liftM hexStr2Int $ many1 hexDigitc char '-'
Response to Conal Elliot:
Conal, ok, you're one sneaky little b… ;-) I'll have to look at the applicative operators to see what I think of them.
Adventures in parsing
I've long wanted to dip my toes in the Parsec water. I've made some attempts
before, but always stumbled on something that put me in the doldrums for so long
that I managed to repress all memories of ever having tried. A few files
scattered in my ~/devo/test/haskell directory tells the story of my failed
attempts. Until now that is :-)
I picked a nice and regular task for my first real attempt: parsing
/proc/<pid>/maps. First a look at the man-page offers a good description of
the format of a line:
address perms offset dev inode pathname 08048000-08056000 r-xp 00000000 03:0c 64593 /usr/sbin/gpm
So, I started putting together some datatypes. First off the address range:
data Address = Address { start :: Integer, end :: Integer } deriving Show
Then I decided that the 's'/'p' in the permissions should be called Access:
data Access = Shared | Private deriving Show
The basic permissions (rwx) are simply represented as booleans:
data Perms = Perms { read :: Bool, write :: Bool, executable :: Bool, access :: Access } deriving Show
The device is straightforward as well:
data Device = Device { major :: Integer, minor :: Integer } deriving Show
At last I tie it all together in a final datatype that represents a memory region:
data MemRegion = MemRegion { address :: Address, perms :: Perms, offset :: Integer, device :: Device, inode :: Integer, pathname :: String } deriving Show
All types derive Show (and receive default implementations of show, at least
when using GHC) so that they are easy to print.
Now, on to the actual "parsec-ing". Faced with the option of writing it top-down
or bottom-up I chose the latter. However, since the format of a single line in
the maps file is so simple it's easy to imagine what the final function will
look like. I settled on bottom-up since the datatypes provide me with such an
obvious splitting of the line. First off, parsing the address range:
parseAddress = let hexStr2Int = Prelude.read . ("0x" ++) in do start <- many1 hexDigit char '-' end <- many1 hexDigit return $ Address (hexStr2Int start) (hexStr2Int end)
Since the addresses themselves are in hexadecimal and always are of at least
length 1 I use many1 hexDigit to read them. I think it would be safe to assume
the addresses always are 8 characters (at least on a 32-bit machine) so it would
be possible to use count 8 hexDigit but I haven't tried it. I've found two
ways of converting a string representation of a hexadecimal number into an
Integer. Above I use the fact that Prelude.read interprets a string
beginning with 0x as a hexadecimal number. The other way I've found is the
slightly less readable fst . (!! 0) . readHex. According to the man-page the
addresses are separated by a single dash so I've hardcoded that in there.
Testing the function is fairly simple. Using gchi, first load the source file
then use parse:
*Main> parse parseAddress "" "0-1"
Right (Address {start = 0, end = 1})
*Main> parse parseAddress "hhh" "01234567-89abcdef"
Right (Address {start = 19088743, end = 2309737967})
Seems to work well enough. :-)
Next up, parsing the permissions. This is so very straightforward that I don't think I need to comment on it:
parsePerms = let cA a = case a of 'p' -> Private 's' -> Shared in do r <- anyChar w <- anyChar x <- anyChar a <- anyChar return $ Perms (r == 'r') (w == 'w') (x == 'x') (cA a)
For parsing the device information I use the same strategy as for the address range above, this time however the separating charachter is a colon:
parseDevice = let hexStr2Int = Prelude.read . ("0x" ++) in do maj <- many1 digit char ':' min <- many1 digit return $ Device (hexStr2Int maj) (hexStr2Int min)
Next is to tie it all together and create a MemRegion instance:
parseRegion = let hexStr2Int = Prelude.read . ("0x" ++) parsePath = (many1 $ char ' ') >> (many1 $ anyChar) in do addr <- parseAddress char ' ' perm <- parsePerms char ' ' offset <- many1 hexDigit char ' ' dev <- parseDevice char ' ' inode <- many1 digit char ' ' path <- parsePath <|> string "" return $ MemRegion addr perm (hexStr2Int offset) dev (Prelude.read inode) path
The only little trick here is that there are lines that lack the pathname. Here's an example from the man-page:
address perms offset dev inode pathname 08058000-0805b000 rwxp 00000000 00:00 0
It should be noted that it seems there is a space after the inode entry so I
keep a char ' ' in the main function. Then I try to parse the line for a path,
if there is none that attempt will fail immediately and instead I parse for an
empty string, parsePath <|> string "". The pathname seems to be prefixed with
a fixed number of spaces, but I'm lazy and just consume one or more. I'm not
sure exactly what characters are allowed in the pathname itself so I'm lazy once
more and just gobble up whatever I find.
To exercise what I had so far I decided to write a function that reads the
maps file for a specific process, based on its pid, parses the contents and
collects all the MemRegion instances in a list.
getMemRegions pid = let fp = "/proc" </> show pid </> "maps" doParseLine' = parse parseRegion "parseRegion" doParseLine l = case (doParseLine' l) of Left _ -> error "Failed to parse line" Right x -> x in do mapContent <- liftM lines $ readFile fp return $ map doParseLine mapContent
The only thing that really is going on here is that the lines are passed from inside an IO monad into the Parser monad and then back again. After this I can try it out by:
*Main> getMemRegions 1
This produces a lot of output so while playing with it I limited the mapping to
the four first lines by using take. The last line then becomes:
return $ map doParseLine (take 4 mapContent)
Now it's easy to add a main that uses the first command line argument as the
pid:
main = do pid <- liftM (Prelude.read . (!! 0)) getArgs regs <- getMemRegions pid mapM_ (putStrLn . show) regs
Well, that concludes my first adventure in parsing :-)
Edit (27-05-2007): I received an email asking for it so here are the import statements I ended up with:
import Control.Monad import System import System.FilePath import Text.ParserCombinators.Parsec
Comment by Conal Elliot:
Congrats on your parser!
Here's an idea that for getting more functional/applicative formulations.
Replace all of the explicitly sequential (do) parsec code with liftM,
liftM2, …. From a quick read-through, I think you can do it. For
parseRegion, you could use an auxiliary function that discards a following
space, e.g. thenSpace (many1 digit).
Also, play with factoring out some of the repeated patterns in parseAddress,
parsePerms and parseDevice.
The more I play with refactoring in my code, the more elegant it gets and the more insight I get. Have fun!
Response to Conal:
Good suggestion. At least if I understand what you mean :-)
Something along the lines of
thenChar c f = f >>= (\ r -> char c >> return r)
with a specialised one for spaces maybe
thenSpace = thenChar ' '
I suppose liftM and friends can be employed to remove the function calling in
the creation of Address, Device and MemRegion. I'll try to venture into
Parsec territory once again soon and report on my findings. :-)