Posts tagged "emacs":
Jumping to errors in Evil
Recently I realised that it'd be really nice if jumping to errors would store the previous location in the Evil jump list. These definitions do just that
(evil-define-motion mes/evil-goto-next-error (count)
:jump t
(unless (bound-and-true-p flymake-mode) (signal 'search-failed nil))
(flymake-goto-next-error count))
(evil-define-motion mes/evil-goto-prev-error (count)
:jump t
(unless (bound-and-true-p flymake-mode) (signal 'search-failed nil))
(flymake-goto-prev-error count))
and for now I've bound them to C-j and C-k (because that's what
evil-collection does)
(general-def flymake-mode-map
:states 'normal
"C-j" 'mes/evil-goto-next-error
"C-k" 'mes/evil-goto-prev-error)
This makes it easier to make a change, fix the errors caused by the change and then return to where I was.
Follow-up on switching to eglot
Jan G sent me a two-part comment.
Part one
I was under the impression that when using elpaca you needed to disable use-package, and that when using elpaca-use-package, you were redefining the macro. I’m not 100% sure about this, but the documentation has an example of use-package and how it actually expands to an elpaca command.
I wouldn't know. All I can say is that it would be nice if package managers that
hook into, or completely redefines use-package, would document if they deviate
from the behaviour of "vanilla use-package" in some way.
Part two
Given that, use-package’s documentation is always going to be a little off, since elpaca is doing everything async. The only way I’ve found to reliably manage some dependencies is to use the elpaca-after-init hook, so they don’t even try to run until elpaca is finished loading everything.
I'd say it sometimes seems like the documentation for use-package is a little
off for use-package itself 🙂
The README for Elpaca says that
Add configuration which relies on after-init-hook, emacs-startup-hook, etc to elpaca-after-init-hook so it runs after Elpaca has activated all queued packages.
but that seems like a very big hammer and as I understand it I'd have to move
the whole :init block for python-mode into the hook in that case. Playing
around with the various blocks for use-package isn't too time consuming and I
think it's a good first thing to try.
Secrets when connecting to DBs
I should have dealt with comments I got to my posts on how I deal with secrets in my work notes, here, and here. Better late than never though, I hope.
Comment from Stefano R
The first one is a link to post titled How I use :dbconnection in org files. It
describes a nice way of setting sql-connection-alist based on the contents of
a file, in his case ~/.pgppass.
Comment from Harald J
The other starts with a function for searching ~/.authinfo.gpg for entries of
the form
machine <host>/<dbname> login <username> password <password> port <port>
and then setting sql-password-search-wallet-function and sql-password-wallet
to tell sql-mode to use it
(defun my/sql-auth-source-search-wallet (wallet product user server database port)
"Read auth source WALLET to locate the USER secret.
Sets `auth-sources' to WALLET and uses `auth-source-search' to locate the entry.
The DATABASE and SERVER are concatenated with a slash between them as the
host key."
(when-let (results (auth-source-search :host (concat server "/" database)
:user user
:port (number-to-string port)))
(when (and (= (length results) 1)
(plist-member (car results) :secret))
(plist-get (car results) :secret))))
(setq sql-password-search-wallet-function #'my/sql-auth-source-search-wallet)
(setq sql-password-wallet "~/.authinfo.gpg")
The value for sql-connection-alist is then as normal
(setq sql-connection-alist
'((some-dbname (sql-product 'oracle)
(sql-port 1521)
(sql-server ...)
...))
and the blocks in orgmode looks like this
SRC sql-mode :product oracle :dbconnection i3v1e-ro :results raw
SELECT to_char(sysdate, 'YYYY-MM-DD HH24:ii:ss') AS today,
to_char(sysdate + 1, 'YYYY-MM-DD HH24:ii:ss') AS tomorrow
FROM dual;
SRC
Thoughts
Both of these feel closer to the intent of sql-mode in a way. I'll have to try
using sql-connection-alist at some point.
Switching to project.el
I've used projectile ever since I created my own Emacs config. I have a vague memory choosing it because some other package only supported it. (It might have been lsp-mode, but I'm not sure.) Anyway, now that I'm trying out eglot, again, I thought I might as well see if I can switch to project.el, which is included in Emacs nowadays.
A non-VC project marker
Projectile allows using a file, .projectile, in the root of a project. This
makes it possible to turn a folder into a project without having to use version
control. It's possible to configure project.el to respect more VC markers than
what's built-in. This can be used to define a non-VC marker.
(setopt project-vc-extra-root-markers '(".projectile" ".git"))
Since I've set vc-handled-backends to nil (the default made VC interfere
with magit, so I turned it off completely) I had to add ".git" to make git
repos be recognised as projects too.
Xref history
The first thing to solve was that the xref stack wasn't per project. Somewhat
disappointingly there only seems to be two options for xref-history-storage
shipped with Emacs
xref-global-history- a single global history (the default)
xref-window-local-history- a history per window
I had the same issue with projectile, and ended up writing my own package for it. For project.el I settled on using xref-project-history.
(use-package xref-project-history
:ensure (:type git
:repo "https://codeberg.org/imarko/xref-project-history.git"
:branch "master")
:custom
(xref-history-storage #'xref-project-history))
Jumping between implementation and test
Projectile has a function for jumping between implementation and test. Not too
surprisingly it's called projectile-toggle-between-implementation-and-test. I
found some old emails in an archive suggesting that project.el might have had
something similar in the past, but if that's the case it's been removed by now.
When searching for a package I came across this email comparing tools for
finding related files. The author mentions two that are included with Emacs
ff-find-other-file- part of find-file.el, which a few other functions and a rather impressive set of settings to customise its behaviour.
find-sibling-file- a newer command, I believe, that also can be customised.
So, there are options, but neither of them are made to work nicely with project.el out of the box. My most complicated use case seems to be in Haskell projects where modules for implementation and test live in separate (mirrored) folder hierarchies, e.g.
src
└── Sider
└── Data
├── Command.hs
├── Pipeline.hs
└── Resp.hs
test
└── Sider
└── Data
├── CommandSpec.hs
├── PipelineSpec.hs
└── RespSpec.hs
I'm not really sure how I'd configure find-sibling-rules, which are regular
expressions, to deal with folder hierarchies like this. To be honest, I didn't
really see a way of configuring ff-find-other-file at first either. Then I
happened on a post about switching between a module and its tests in Python.
With its help I came up with the following
(defun mes/setup-hs-ff ()
(when-let* ((proj-root (project-root (project-current)))
(rel-proj-root (-some--> (buffer-file-name)
(file-name-directory it)
(f-relative proj-root it)))
(sub-tree (car (f-split (f-relative (buffer-file-name) proj-root))))
(search-dirs (--> '("src" "test")
(remove sub-tree it)
(-map (lambda (p) (f-join proj-root p)) it)
(-select #'f-directory? it)
(-mapcat (lambda (p) (f-directories p nil t)) it)
(-map (lambda (p) (f-relative p proj-root)) it)
(-map (lambda (p) (f-join rel-proj-root p)) it))))
(setq-local ff-search-directories search-dirs
ff-other-file-alist '(("Spec\\.hs$" (".hs"))
("\\.hs$" ("Spec.hs"))))))
A few things to note
- The order of rules in
ff-other-file-alistis important, the first match is chosen. (buffer-file-name)can, and really does, returnnilat times, andfile-name-directorydoesn't deal with anything but strings.- The entries in
ff-search-directorieshave to be relative to the file in the current buffer, hence the rather involvedvarlistin thewhen-let*expression.
With this in place I get the following values for ff-search-directories
src/Sider/Data/Command.hs("../../../test/Sider" "../../../test/Sider/Data")test/Sider/Data/CommandSpec.hs("../../../src/Sider" "../../../src/Sider/Data")
And ff-find-other-file works beautifully.
Conclusion
My setup with project.el now covers everything I used from projectile so I'm fairly confident I'll be happy keeping it.
Using advice to limit lsp-ui-doc nuisance
I've switched back to lsp-mode temporarily until I've had time to fix a few
things with my eglot setup. Returning prompted me to finally address an
irritating behaviour with lsp-ui-doc.
No matter what I set lsp-ui-doc-position to it ends up covering information
that I want to see. While waiting for a fix I decided to work around it. It
seems to me that this is exactly what advice is for.
I came up with the following to make sure the frame appears on the half of the
buffer where point isn't.
(defun my-lsp-ui-doc-wrapper (&rest _)
(let* ((pos-line (- (line-number-at-pos (point))
(line-number-at-pos (window-start))))
(pos (if (<= pos-line (/ (window-body-height) 2))
'bottom
'top)))
(setopt lsp-ui-doc-position pos)))
(advice-add 'lsp-ui-doc--move-frame :before #'my-lsp-ui-doc-wrapper)
More on the switch to eglot
Since the switching to eglot I've ended up making a few related changes.
Replacing flycheck with flymake
Since eglot it's written to work with other packages in core, which means it
integrates with flymake. The switch comprised
- Use
:ensure nilto make sureelpacaknows there's nothing to download. - Add a call to
flymake-modetoprog-mode-hook. - Define two functions to toggle showing a list of diagnostics for the current buffer and the project.
- Redefine the relevant keybindings.
The two functions for toggling showing diagnostics look like this
(defun mes/toggle-flymake-buffer-diagnostics ()
(interactive)
(if-let* ((window (get-buffer-window (flymake--diagnostics-buffer-name))))
(save-selected-window (quit-window nil window))
(flymake-show-buffer-diagnostics)))
(defun mes/toggle-flymake-project-diagnostics ()
(interactive)
(if-let* ((window (get-buffer-window (flymake--project-diagnostics-buffer (projectile-project-root)))))
(save-selected-window (quit-window nil window))
(flymake-show-project-diagnostics)))
And the changed keybindings are
| flycheck | flymake |
|---|---|
| flycheck-next-error | flymake-goto-next-error |
| flycheck-previous-error | flymake-goto-prev-error |
| mes/toggle-flycheck-error-list | mes/toggle-flymake-buffer-diagnostics |
| mes/toggle-flycheck-projectile-error-list | mes/toggle-flymake-project-diagnostics |
Using with-eval-after-load instead of :after eglot
When it comes to use-package I keep on being surprised, and after the switch
to elpaca I've found some new surprises. One of them was that using :after
eglot like this
(use-package haskell-ng-mode
:afer eglot
:ensure (:type git
:repo "git@gitlab.com:magus/haskell-ng-mode.git"
:branch "main")
:init
(add-to-list 'major-mode-remap-alist '(haskell-mode . haskell-ng-mode))
(add-to-list 'eglot-server-programs '(haskell-ng-mode "haskell-language-server-wrapper" "--lsp"))
(setq-default eglot-workspace-configuration
(plist-put eglot-workspace-configuration
:haskell
'(:formattingProvider "fourmolu"
:plugin (:stan (:global-on :json-false)))))
...
:hook
(haskell-ng-mode . eglot-ensure)
...)
would delay initialisation until after eglot had been loaded. However, it
turned out that nothing in :init ... seemed to run and upon opening a haskell file
no mode was loaded.
After a bit of thinking and tinkering I got it working by removing :after
eglot and using with-eval-after-load
(use-package haskell-ng-mode
:ensure (:type git
:repo "git@gitlab.com:magus/haskell-ng-mode.git"
:branch "main")
:init
(add-to-list 'major-mode-remap-alist '(haskell-mode . haskell-ng-mode))
(with-eval-after-load 'eglot
(add-to-list 'eglot-server-programs '(haskell-ng-mode "haskell-language-server-wrapper" "--lsp"))
(setq-default eglot-workspace-configuration
(plist-put eglot-workspace-configuration
:haskell
'(:formattingProvider "fourmolu"
:plugin (:stan (:global-on :json-false))))))
...
:hook
(haskell-ng-mode . eglot-ensure)
...)
That change worked for haskell, and it seemed to work for python too, but after a little while I realised that python needed a bit more attention.
Getting the configuration for Python to work properly
The python setup looked like this
(use-package python
:init
(add-to-list 'major-mode-remap-alist '(python-mode . python-ts-mode))
(with-eval-after-load 'eglot
(assoc-delete-all '(python-mode python-ts-mode) eglot-server-programs)
(add-to-list 'eglot-server-programs
`((python-mode python-ts-mode) . ,(eglot-alternatives
'(("rass" "python") "pylsp")))))
...
:hook (python-ts-mode . eglot-ensure)
...)
and it worked all right, but then I visited the package (using elpaca-visit)
and realised that the downloaded package was all of emacs. That's a bit of
overkill, I'd say.
However, adding :ensure nil didn't have the expected effect of just using the
version that's in core. Instead the whole configuration seemed to never take
effect and again I was back to the situation where I had to jump to
python-ts-mode manually.
The documentation for use-package says that :init is for
Code to run before PACKAGE-NAME has been loaded.
but I'm guessing "before" isn't quite before enough. Then I noticed :preface
with the description
Code to be run before everything except
:disabled; this can be used to define functions for use in:if, or that should be seen by the byte-compiler.
and yes, "before everything" is early enough. The final python configuration looks like this
(use-package python
:ensure nil
:preface
(add-to-list 'major-mode-remap-alist '(python-mode . python-ts-mode))
:init
(with-eval-after-load 'eglot
(assoc-delete-all '(python-mode python-ts-mode) eglot-server-programs)
(add-to-list 'eglot-server-programs
`((python-mode python-ts-mode) . ,(eglot-alternatives
'(("rass" "python") "pylsp")))))
...
:hook (python-ts-mode . eglot-ensure)
...)
Closing remark
I'm still not sure I have the correct intuition about how to use use-package,
but hopefully it's more correct now than before. I have a growing suspicion
that use-package changes behaviour based on the package manager I use. Or
maybe it's just that some package managers make use-package more forgiving of
bad use.
Trying eglot, again
I've been using lsp-mode since I switched to Emacs several years ago. When eglot
made into Emacs core I used it very briefly but quickly switched back. Mainly I
found eglot a bit too bare-bones; I liked some of the bells and whistles of
lsp-ui. Fast-forward a few years and I've grown a bit tired of those bells and
whistles. Specifically that it's difficult to make lsp-ui-sideline and
lsp-ui-doc work well together. lsp-ui-sidedline is shown on the right side,
which is good, but combining it with lsp-ui-doc leads to situations where the
popup covers the sideline. What I've done so far is centre the line to bring the
sideline text out. I was playing a little bit with making the setting of
lsp-ui-doc-position change depending on the location of the current position.
It didn't work that well though so I decided to try to find a simpler setup.
Instead of simplifying the setup of lsp-config I thought I'd give eglot
another shot.
Basic setup
I removed the statements pulling in lsp-mode, lsp-ui, and all
language-specific packages like lsp-haskell. Then I added this to configure
eglot
(use-package eglot
:ensure nil
:custom
(eglot-autoshutdown t)
(eglot-confirm-server-edits '((eglot-rename . nil)
(t . diff))))
The rest was mainly just switching lsp-mode functions for eglot functions.
| lsp-mode function | eglot function |
|---|---|
lsp-deferred |
eglot-ensure |
lsp-describe-thing-at-point |
eldoc |
lsp-execute-code-action |
eglot-code-actions |
lsp-find-type-definition |
eglot-find-typeDefinition |
lsp-format-buffer |
eglot-format-buffer |
lsp-format-region |
eglot-format |
lsp-organize-imports |
eglot-code-action-organize-imports |
lsp-rename |
eglot-rename |
lsp-workspace-restart |
eglot-reconnect |
lsp-workspace-shutdown |
eglot-shutdown |
I haven't verified that the list is fully correct yet, but it looks good so far.
The one thing I might miss is lenses, and using lsp-avy-lens. However,
everything that I use lenses for can be done using actions, and to be honest I
don't think I'll miss the huge lens texts from missing type annotations in
Haskell.
Configuration
One good thing about lsp-mode's use of language-specific packages is that
configuration of the various servers is performed through functions. This makes
it easy to discover what options are available, though it also means not all
options may be available. In eglot configuration is less organised, I have to
know about the options for each language server and put the options into
eglot-workspace-configuration myself. It's not always easy to track down what
options are available, and I've found no easy way to verify the settings. For
instance, with lsp-mode I configures HLS like this
(lsp-haskell-formatting-provider "fourmolu")
(lsp-haskell-plugin-stan-global-on nil)
which translates to this for eglot
(setq-default eglot-workspace-configuration
(plist-put eglot-workspace-configuration
:haskell
'(:formattingProvider "fourmolu"
:plugin (:stan (:global-on :json-false)))))
and I can verify that this configuration has taken effect because I know enough about the Haskell tools.
I do some development in Python and I used to configure pylsp like this
(lsp-pylsp-plugins-mypy-enabled t)
(lsp-pylsp-plugins-ruff-enabled t)
which I think translates to this for eglot
(setq-default eglot-workspace-configuration
(plist-put eglot-workspace-configuration
:pylsp
'(:plugins (:ruff (:enabled t)
:mypy (:enabled t)))))
but I don't know any convenient way of verifying these settings. I'm simply not
familiar enough with the Python tools. I can check the value of
eglot-workspace-configuration by inspecting it or calling
eglot-show-workspace-configuration but is there really no way of asking the
language server for its active configuration?
Closing remark
The last time I gave up on eglot very quickly, probably too quickly to be
honest. I made these changes to my configuration over the weekend, so the real
test of eglot starts when I'm back in the office. I have a feeling I'll stick
to it longer this time.
Making a theme based on modus
In modus-theme 5.0.0 Prot introduced a structured way to build a theme based
on modus. Just a few days ago he released version 5.1.0 with some improvements
in this area.
The official documentation of how to build on top of the Modus themes is very good. It's focused on how to make sure your theme fits in with the rest of the "modus universe". However, after reading it I still didn't have a good idea of how to get started with my own theme. In case others feel the same way I thought I'd write down how I ended up getting started.
The resulting theme, modus-catppuccin, can be found here.
A little background
I read about how to create a catppuccin-mocha theme using modus-vivendi through
modus' mechanism of overrides. On Reddit someone pointed out that Prot had been
working on basing themes on modus and when I checked the state of it he'd just
released version 5.0.0. Since I'm using catppuccin themes for pretty much all
software with a GUI I thought it could be interesting to see if I could make a
modus-based catppuccin theme to replace my use of catppuccin-theme.
I'm writing the rest as if it was a straight and easy journey. It wasn't! I made a few false starts, each time realising something new about the structure and starting over with a better idea.
Finding a starting point
When reading what Prot had written about modus-themes in general, and about
how to create themes based on it, in particular, I found that he's ported both
standard-themes and ef-themes so they now are based on modus. Instead of
just using them for inspiration I decided that since standard-themes is so
small I might as well use it as my starting point.
Starting
I copied all files of standard-themes to an empty git repository, then I
- deleted all but one of the theme file
- copied the remaining theme file so I had four in total (one for each of the catppuccin flavours)
- renamed constants, variables, and functions so they would match the theme and its flavours
- put the colours into each
catppuccin-<flavour>-palette - emptied the common palette,
modus-catppuccin-common-palette-mappings - made sure that my use of
modus-themes-themewas reasonable, in particular the base palette (I based the light flavour onmodus-operandiand the three dark flavours onmodus-vivendi)
The result can be seen here.
At this point the three theme flavours contained no relevant mappings of their
own, so what I had was in practice modus-operandi under a new name and
modus-vivendi under three new names.
Adding mappings for catppuccin
By organising the theme flavours the way outlined above I only need to add
mappings to modus-catppuccin-common-palette-mappings because
- each flavour-specific mapping adds its colour palette using the same name (that's how catppuccin organises its colors too, as seen here)
- each flavour-specific mapping is combined with the common one
- any missing mapping is picked up by the underlying theme,
modus-operandiormodus-vivendi, so there will be (somewhat) nice colours for everything
I started out with the mappings in the dark standard theme but then I realised
that's not the complete list of available mappings and I started looking at the
themes in modus-themes itself.
Current state of modus-catppuccin
I've so far defined enough mappings to make it look enough like catppuccin for
my use. There are a lot of possible mappings so my plan is to add them over time
and use catppuccin-theme for inspiration.
Listing buffers by tab using consult and bufferlo
I've gotten into the habit of using tabs, via tab-bar, to organise my buffers
when I have multiple projects open at once. Each project has its own tab.
There's nothing fancy here (yet), I simply open a new tab manually before
opening a new project.
A while ago I added bufferlo to my config to help with getting consult-buffer
to organise buffers (somewhat) by tab. I copied the configuration from the
bufferlo README and started using it. It took me a little while to notice that
the behaviour wasn't quite what I wanted. It seemed like one buffer "leaked"
from another tab.
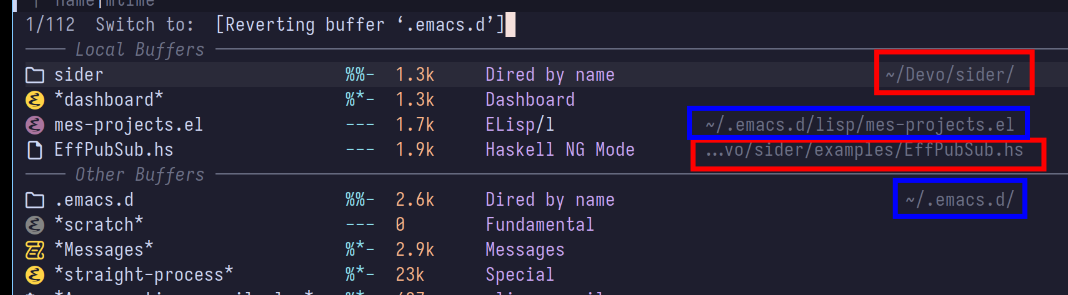
In the image above all files in ~/.emacs.d should be listed under Other
Buffers, but one has been brought over into the tab for the Sider project.
After a bit of experimenting I realised that
- the buffer that leaks is the one I'm in when creating the new tab, and
- my function for creating a new tab doesn't work the way I thought.
My function for creating a new tab looked like this
(lambda ()
(interactive)
(tab-new)
(dashboard-open))
and it turns out that tab-new shows the current buffer in the new tab which in
turn caused bufferlo to associate it to the wrong tab. From what I can see
there's no way to tell tab-new to open a specific buffer in the newly created
tab. I tried the following
(lambda ()
(interactive)
(with-current-buffer dashboard-buffer-name
(tab-new)))
hoping that the dashboard would open in the new tab. It didn't, it was still the active buffer that popped up in the new tab.
In the end I resorted to use bufferlo-remove to simply remove the current
buffer from the new tab.
(lambda ()
(interactive)
(tab-new)
(bufferlo-remove (current-buffer))
(dashboard-open))
No more leakage and consult-buffer works like I wanted it to.
Reviewing GitHub PRs in Emacs
My Emacs config's todo-list has long had an item about finding some way to review GitHub PRs without having to leave Emacs and when the forge issue that I subscribe to came alive again I thought it was time to see if I can improve my config.
I found three packages for doing reviews
I've tried the first one before but at the time it didn't seem to work at all. Apparently that's improved somewhat, though there's a PR with a change that's necessary to make it work.1 The first two don't support comments on multiple lines of a PR, there are issues/discussions for both
code-review: Code suggestion on multiple linesgithub-review: Multi-line code comments
The last one, emacs-pr-review does support commenting on multiple lines, but
it lacks a nice way of opening a review from magit. What I can do is
- position the cursor on a PR in the
magitstatus view, then - copy the the PR's URL using
forge-copy-url-at-point-as-kill, and - open the PR by calling
pr-reviewand pasting the PR's URL.
Which I did for a few days until I got tired of it and wrote a function to cut out they copy/paste part.
(defun mes/pr-review-via-forge () (interactive) (if-let* ((target (forge--browse-target)) (url (if (stringp target) target (forge-get-url target))) (rev-url (pr-review-url-parse url))) (pr-review url) (user-error "No PR to review at point")))
I've bound it to a key in magit-mode-map to make it easier.
I have to say I'm not completely happy with emacs-pr-review, so if either of
the other two sort out commenting on multiple lines I'll check them out again.
My full setup for pr-review is here.
Footnotes:
The details can be found among the comments of the forge issue.
Followup on secrets in my work notes
I got the following question on my post on how I handle secrets in my work notes:
Sounds like a nice approach for other secrets but how about
:dbconnectionfor Orgmode andsql-connection-alist?
I have to admit I'd never come across the variable sql-connection-alist
before. I've never really used sql-mode for more than editing SQL queries and
setting up code blocks for running them was one of the first things I used
yasnippet for.
I did a little reading and unfortunately it looks like sql-connection-alist
can only handle string values. However, there is a variable
sql-password-search-wallet-function, with the default value of
sql-auth-source-search-wallet, so using auth-source is already supported for
the password itself.
There seems to be a lack of good tutorials for setting up sql-mode in a secure
way – all articles I found place the password in clear-text in the config –
filling that gap would be a nice way to contribute to the Emacs community. I'm
sure it'd prompt me to re-evaluate incorporating sql-mode in my workflow.
Improving how I handle secrets in my work notes
At work I use org-mode to keep notes about useful ways to query our systems, mostly that involves using the built-in SQL support to access DBs and ob-http to send HTTP requests. In both cases I often need to provide credentials for the systems. I'm embarrassed to admit it, but for a long time I've taken the easy path and kept all credentials in clear text. Every time I've used one of those code blocks I've thought I really ought to find a better way of handling these secrets one of these days. Yesterday was that day.
I ended up with two functions that uses auth-source and its ~/.authinfo.gpg
file.
(defun mes/auth-get-pwd (host) "Get the password for a host (authinfo.gpg)" (-> (auth-source-search :host host) car (plist-get :secret) funcall)) (defun mes/auth-get-key (host key) "Get a key's value for a host (authinfo.gpg) Not usable for getting the password (:secret), use 'mes/auth-get-pwd' for that." (-> (auth-source-search :host host) car (plist-get key)))
It turns out that the library can handle more keys than the documentation
suggests so for DB entries I'm using a machine (:host) that's a bit shorter
and easier to remember than the full AWS hostname. Then I keep the DB host and
name in dbhost (:dbhost) and dbname (:dbname) respectively. That makes
an entry look like this:
machine db.svc login user port port password pwd dbname dbname dbhost dbhost
If I use it in a property drawer it looks like this
:PROPERTIES: :header-args:sql: :engine postgresql :header-args:sql+: :dbhost (mes/auth-get-key "db.svc" :dbhost) :header-args:sql+: :dbport (string-to-number (mes/auth-get-key "db.svc" :port)) :header-args:sql+: :dbuser (mes/auth-get-key "db.svc" :user) :header-args:sql+: :dbpassword (mes/auth-get-pwd "db.svc") :header-args:sql+: :database (mes/auth-get-key "db.svc" :dbname) :END:
Removing symlink question
I'm not sure why, but all of a sudden I started getting this question every time emacs starts
Symbolic link to Git-controlled source file; follow link?
After some searching I found out that it's VC asking. I'm guessing this comes from straight's very liberal use of symlinks. Though I'm still a little surprised at VC kicking in when reading the config.
Anyway, there are two variables to consider, vc-follow-symlinks and
vc-handled-backends. I opted to modify the latter one, and since I don't use
VC at all I'm turning it off completely.
(setopt vc-handled-backends nil)
Emacs via Nix with mu4e
I've been running development versions of Emacs ever since I switched to Wayland
and needed the PGTK code. The various X-git packages on AUR makes that easy,
as long as one doesn't mind building the packages locally, and regularly.
Building a large package like Emacs does get a bit tiring after a while though
so I started looking at the emacs overlay to see if I could keep up without
building quite that much.
The first attempt at this failed as I couldn't get my email setup working; emacs
simply refused to find the locally installed mu4e package. I felt I didn't
have time to solve it at the time, reverted back to doing the builds myself
again. It kept irritating me though, and today I made another attempt. This time
I invested a bit more time in reading up on how to install emacs via Nix with
packages. Something that paid off.
I'm managing my packages using nix profile and a flake.nix. To install emacs
with a working mu4e I started with adding the emacs overlay to the inputs
inputs = { nixpkgs.url = "github:nixos/nixpkgs?ref=nixpkgs-unstable"; ... community-emacs.url = "github:nix-community/emacs-overlay"; };
and in my outputs I made sure to use the overlay on nixpkgs
outputs = inputs@{ nixpkgs, community-emacs, ... }: let system = "x86_64-linux"; pkgs = import nixpkgs { inherit system; overlays = [ community-emacs.overlays.emacs ]; }; ...
and in the list of packages passed to pkgs.buildEnv I added
... ((emacsPackagesFor emacs-pgtk).emacsWithPackages (epkgs: [ epkgs.mu4e ])) mu ...
That's all there's to it. After running nix profile update 0 I had a build of
emacs with Wayland support that's less than a day old, all downloaded from the
community cache. Perfect!
A function for jumping to a project TODO file
I've had org-projectile in my config since the beginning, and while it's worked nicely for me in my main config it gave me some grief when I played around with elpaca the other week.1
I tried to get the install instructions to work, but kept on getting errors when
loading my config. Given that I only use it for one thing, to open the file
TODO.org in the current project's root, I decided to just write a function for
doing that instead.
(defun mep-projectile-open-todo () "Open the project's todo file." (interactive) (if-let* ((proj-dir (projectile-project-root)) (proj-todo-file (f-join proj-dir "TODO.org"))) (org-open-file proj-todo-file) (message "Not in a project")))
Footnotes:
Orderless completion in lsp-mode
If you, like me, are using corfu to get in-buffer completion and extend it with orderless to make it even more powerful, you might have noticed that you lose the orderless style as soon as you enter lsp-mode.
My setup of orderless looks like this
(use-package orderless :custom (orderless-matching-styles '(orderless-literal orderless-regexp orderless-flex)) (completion-styles '(orderless partial-completion basic)) (completion-category-defaults nil) (completion-category-overrides '((file (styles partial-completion)))))
which basically turns on orderless style for all things except when completing filenames.
It turns out that lsp-mode messes around with completion-category-defaults
and when entering lsp-mode this code here adds a setting for 'lsp-capf.
Unfortunately there seems to be no way to prevent lsp-mode from doing this so
the only option is to fix it up afterwards. Luckily there's a hook for running
code after the completion for lsp-mode is set up, lsp-completion-mode-hook.
Adding the following function to it makes sure I now get to enjoy orderless
also when writing code.
(lambda () (setq-local completion-category-defaults (assoc-delete-all 'lsp-capf completion-category-defaults)))
Making Emacs without terminal emulator a little more usable
After reading Andrey Listopadov's You don't need a terminal emulator (mentioned
at Irreal too) I decided to give up on using Emacs as a terminal for my shell.
In my experience Emacs simply isn't a very good terminal to run a shell in
anyway. I removed the almost completely unused shell-pop from my configuration
and the keybinding with a binding to async-shell-command. I'm keeping
terminal-here in my config for the time being though.
I realised projectile didn't have a function for running it in the root of a
project, so I wrote one heavily based on project-async-shell-command.
(defun mep-projectile-async-shell-command () "Run `async-shell-command' in the current project's root directory." (declare (interactive-only async-shell-command)) (interactive) (let ((default-directory (projectile-project-root))) (call-interactively #'async-shell-command)))
I quickly found that the completion offered by Emacs for shell-command and
async-shell-command is far from as sophisticated as what I'm used to from Z
shell. After a bit of searching I found emacs-bash-completion. Bash isn't my
shell of choice, partly because I've found the completion to not be as good as
in Z shell, but it's an improvement over what stock Emacs offers. The
instructions in the repo was good, but had to be adjusted slightly:
(use-package bash-completion :straight (:host github :repo "szermatt/emacs-bash-completion") :config (add-hook 'shell-dynamic-complete-functions 'bash-completion-dynamic-complete))
I just wish I'll find a package offering completions reaching Z shell levels.
Using the golang mode shipped with Emacs
A few weeks ago I wanted to try out tree-sitter and switched a few of the modes
I use for coding to their -ts-mode variants. Based on the excellent How to Get
Started with Tree-Sitter I added bits like this to the setup I have for coding
modes:1
(use-package X-mode :init (add-to-list 'treesit-language-source-alist '(X "https://github.com/tree-sitter/tree-sitter-X")) ;; (treesit-install-language-grammar 'X) (add-to-list 'major-mode-remap-alist '(X-mode . X-ts-mode)) ;; ... )
I then manually evaluated the expression that's commented out to download and
compile the tree-sitter grammar. It's a rather small change, it works, and I can
switch over language by language. I swapped a couple of languages to the
tree-sitter modes like this, including golang. The only mode that I noticed
changes in was golang, in particular my adding of gofmt-before-save to
before-save-hook had stopped having any effect.
What I hadn't realised was that the go-mode I was using didn't ship with Emacs
and that when I switched to go-ts-mode I switched to one that was. It turns
out that gofmt-before-save is hard-wired to work only in go-mode,
something others have noticed.
I don't feel like waiting for go-mode to fix that though, especially not when
there's a perfectly fine golang mode shipping with Emacs now, and not when
emacs-reformatter make it so easy to define formatters (as I've written about
before).
My golang setup, sans keybindings, now looks like this:2
(use-package go-ts-mode :hook (go-ts-mode . lsp-deferred) (go-ts-mode . go-format-on-save-mode) :init (add-to-list 'treesit-language-source-alist '(go "https://github.com/tree-sitter/tree-sitter-go")) (add-to-list 'treesit-language-source-alist '(gomod "https://github.com/camdencheek/tree-sitter-go-mod")) ;; (dolist (lang '(go gomod)) (treesit-install-language-grammar lang)) (add-to-list 'auto-mode-alist '("\\.go\\'" . go-ts-mode)) (add-to-list 'auto-mode-alist '("/go\\.mod\\'" . go-mod-ts-mode)) :config (reformatter-define go-format :program "goimports" :args '("/dev/stdin")) :general ;; ... )
So far I'm happy with the built-in go-ts-mode and I've got to say that using a
minor mode for the format-on-save functionality is more elegant than adding a
function to before-save-hook (something that go-mode may get through this
PR).
Footnotes:
How I use Emacs
I've recently written two posts about my attempts to use a slimmed down Emacs
setup for some very specific use cases. I'be put both posts on Reddit, here and
here, and in both cases the majority of comments have been telling me that I
should use emacsclient. I know they have good intentions – they want to share
insight they've gained and benefit from on a daily basis. However, no matter how
many Emacs devotees point out the benefits of emacsclient I'm not about to
start using it. This post is an attempt to answer why that is.
Up front I want to clarify a few things:
- Yes, I know how to use
emacsclient, and - yes, I know it is a good way to, in a way, improve Emacs startup time,1 and
- yes, I know how to turn on
server-modein Emacs, and finally - yes, I know how to run Emacs using a user unit for SystemD.
With that out of the way, here are the two ways I use Emacs
- As my starting point for work, i.e. writing code, keeping notes, tracking time, and writing my daily work journal.
- As my editor of ephemeral files.2
The next two sections explain more about these two distinct ways I use Emacs
As my starting point for work
| Number of packages | 162 |
Init time (emacs-init-time) |
1.883483s |
Config size (by du -bch) |
68K |
Much of what I do on a daily basis starts in Emacs. I typically have one
instance of Emacs open and I always keep it on the second virtual desktop. I
always run it in the GUI. When I write code I start with opening a new tab, then
I open a dired buffer in the project's folder (by using consult-projectile).
When I need a terminal I open it from Emacs using on of
terminal-here-project-launch or terminal-here. Occasionally I open a shell
prompt inside Emacs using shell-pop.
Back when I used Vim as my main editor I always started a terminal first and
then opened files from there. Since switching to Emacs I've completely stopped
doing that. Over the last 8 or so years of Emacs usage there's only been a
handful of times when I've wanted to open a file from the terminal and I've run
M-x server-start and used emacsclient. The last time was more than a year
ago.
As I typically keep exactly one Emacs open, and I start it soon after logging in, I'm not too concerned with startup time. I think under 2s is more than fast enough given the functionality I have in my setup.
This setup I use for taking notes and writing my daily work journal, as well as reading email, and programming in a half-dozen languages. I have a large-ish set of keybindings that I've set up using general.el, inspired by Spacemacs at first but by now it's started to gain its own character.
As my editor of ephemeral files ($EDITOR)
| Number of packages | 22 |
Init time (emacs-init-time) |
0.209298s |
Config size (by du -bch) |
6.7K |
Ephemeral files are files I tend to edit for less than 30 seconds, maybe a minute at most. There are three main use cases for ephemeral files:
- Searching the scrollback buffer in zellij, and copying bits to the clipboard for various uses.
- Editing files when running
gitfrom the command line. It's not something I do very often, but it happens. - Editing shell commands. When they get a little too large to handle
conveniently using ZSH directly I invoke
edit-command-line.
For a few reasons I decided to make a second, completely separate configuration just to handle ephemeral files.
- It will only be used in a terminal.
- I want to be able to have some special keybindings that suit a specific use, e.g. for the scrollback buffer I've bound `SPC Y` to copy the selected text to the clipboard and then exit Emacs. It's a thing that I use all the time with the scrollback buffer, but never otherwise.
- I have no need, nor any desire, to switch from editing a commit message, or searching a scrollback buffer, to reading email or editing an org-mode file. The complete separation is a feature.
With a startup time of less than a quarter of a second it is well within the
acceptable, and there is absolutely no need to use emacsclient just to speed
things up. Given my desire for separation, I wouldn't want to use my main Emacs
instance as a server and edit ephemeral files anyway.
Conclusion
I've found a setup that seems to work really well and tick all the requirements
I have when it comes to separation between use cases and ability to have custom
keybindings for them. Also, Emacs is starting up very fast with my slimmed
down configuration. If starting Emacs with the slimmed configuration starts
taking too long I'm more likely to go back to using Neovim than complicate
things with emacsclient.
So no, I am not going to start using emacsclient any time soon.
Footnotes:
Using Emacs as $EDITOR
Continuing on from my experiment with using Emacs as for scrollback in my
terminal multiplexer I thought I'd try to use it as my $EDITOR as well.
The two main cases where I use $EDITOR is
- The occasional use of
giton the command line, rebasing or writing a commit message, and - Use of ZSH's
edit-command-linefunctionality.
To make sure Emacs is starting up quickly enough I'm using the same small setup
I created for the scrollback editing, so I'm now setting EDITOR like this
export EDITOR="emacs -nw --init-directory ~/.se.d"
Now that I want to use the same setup for editing I can't really jump into
view-mode every time Emacs starts so I have to be a bit more clever. The
following bit won't do
(add-hook 'find-file-hook #'view-mode)
I need to somehow find out what starts Emacs and then only modify the hook when needed. Unfortunately I haven't found anything that reveals that Emacs is started by zellij. Creating a separate little script that zellij uses would be an option, of course, but for now I've opted to make it the default and instead refrain from adding the hook in the other two use cases.
ZSH doesn't make it easy to find out that it's edit-command-line either, but
as I've observed that the command line sometimes doesn't look right after
leaving the editor I wanted to call redisplay to fix it up. That means I need
to have a function anyway, so using an environment variable becomes an easy way
to check if Emacs is being used to edit the command line.
function se-edit-command-line() { export SE_SKIP_VIEW=y zle edit-command-line unset SE_SKIP_VIEW zle redisplay } zle -N se-edit-command-line bindkey -M vicmd '^V' se-edit-command-line bindkey -M viins '^V' se-edit-command-line
Unfortunately is seems zle edit-command-line doesn't pass on non-exported
environment variables, hence the explicit export and unset.
When git starts an editor it sets a few environment variables so it was easy
to just pick one that is set in both cases I care about. I picked
GIT_EXEC_PATH.
With these things in place I changed the slim setup to only add the hook when neither of the environment variables are present
(unless (or (getenv "SE_SKIP_VIEW") (getenv "GIT_EXEC_PATH")) (add-hook 'find-file-hook #'view-mode))
Hopefully this works out well enough that I won't feel a need to go back to
using Neovim as my $EDITOR.
Defining a formatter for Cabal files
For Haskell code I can use lsp-format-buffer and lsp-format-region to keep
my file looking nice, but I've never found a function for doing the same for
Cabal files. There's a nice command line tool, cabal-fmt, for doing it, but it
means having to jump to a terminal. It would of course be nicer to satisfy my
needs for aesthetics directly from Emacs. A few times I've thought of writing
the function myself, I mean how hard can it be? But then I've forgotten about it
until then next time I'm editing a Cabal file.
A few days ago I noticed emacs-reformatter popping up in my feeds. That removed all reasons to procrastinate. It turned out to be very easy to set up.
The package doesn't have a recipe for straight.el so it needs a :straight
section. Also, the naming of the file in the package doesn't fit the package
name, hence the slightly different name in the use-package declaration:1
(use-package reformatter :straight (:host github :repo "purcell/emacs-reformatter"))
Now the formatter can be defined
(reformatter-define cabal-format :program "cabal-fmt" :args '("/dev/stdin"))
in order to create functions for formatting, cabal-format-buffer and
cabal-format-region, as well as a minor mode for formatting on saving a Cabal
file.
Footnotes:
I'm sure it's possible to use :files to deal with this, but I'm not sure
how and my naive guess failed. It's OK to be like this until I figure it out
properly.
Setting up emacs-openai/chatgpt
Yesterday I decided to try to make more use of the ChatGPT account I have. What prompted it mostly was that I recalled that my employer has a paid subscription and that if we use it enough they'll get us access to ChatGPT4.
After a bit of research1 I decided to start with emacs-open/chatgpg. However, as I found the instructions slightly lacking I'm sharing my setup.
The instructions for straight.el fail to mention that one needs the openai
package too.
(use-package openai :straight (openai :type git :host github :repo "emacs-openai/openai"))
The complete declaration for use-package ended up looking like this:
(use-package chatgpt :straight (chatgpt :type git :host github :repo "emacs-openai/chatgpt") :requires openai :config (setq openai-key #'openai-key-auth-source))
Oh, and don't forget to put an entry into `~/.authinfo.gpg`. Something like this should do it
machine api.openai.com login <anything> password <your key>
Footnotes:
I found Alex Kehayias' note to be a good starting point.
Using emacs for the scrollback in terminal multiplexers
I should start with saying that I still don't really know if this is a good idea or not, but it feels like it's worth trying out at least.
An irritating limitation in Zellij, and a possible solution
After seeing it mentioned in an online community I thought it might be worth trying out. I'm not really disappointed with tmux, I've been using it for years but I actually only use a small part of what it can do. I create tabs, sometimes create panes, and I regularly use the scollback functionality to copy output of commands I've run earlier.
Unfortunately, as is reported in a ticket, Zellij can't select and copy using the keyboard. From the discussion in that ticket it seems unlikely it ever will be able to. After finding that out I resigned to staying with Tmux – I'm not ready to go back to using a pointing device to select and copy text in my terminal!
When I was biking to the pool yesterday I realised a thing though: I'm already using a tool that is very good at manipulating text using the keyboard. Of course I'm talking about Emacs! So if I can just make Emacs start up quickly enough I ought to be able to use it for searching, selecting and copying from the scrollback buffer. I haven't found a way to do this in Tmu= yet, but Zellij has EditScrollBack so I can at least try it out.
A nice benefit is that I can cut back on the number of different shortcuts I use daily.
My slimmed down Emacs config
My current Emacs config starts up in less than 2s, which is good enough as I normally start Emacs at most a few times per day. However, if I have to wait 2s to open the scrollback buffer I suspect I'll tire very quickly and abandon the experiment. So I took my ordinary config and slimmed it down. Cutting away things that weren't related to navigation and searching.
The list of packages is not very long:
straightuse-packageevilgeneralwhich-keyverticoorderlessmarginaliaconsult
The first 5 are for usability in general, and the last 4 are bring in the functions I use for searching through text.
The resulting config starts in less than ¼s. That's more than acceptable, I find.
Copying to the Wayland clipboard
It turns out that copying with `y` in evil does the right thing by default and
the copied text ends up in the clipboard without any special configuration.
From Tmux I'm used to being thrown out of copy-mode after copying something.
While that's sometimes irritating, it's at other times exactly what I want.
Given that evil-yank does the right thing it was easy to write a function for
it:
(defun se/yank-n-kill (beg end) (interactive "r") (evil-yank beg end) (kill-emacs))
The config files
I'm keeping my dot-files in a private repo, but I put a snapshot of the Emacs and Zellij config in a snippet.
Making keymaps prettier with general.el
After my previous post on defining keymaps using general.el I revisited some of
my setup in order to make some package keymaps prettier when displayed by
which-key. The keymaps defined by packages are typically don't contain any
description of the bindings, so which-key ends up displaying the name of the
function bound to the key. It's not always easy to remember what a function does
based just on its name, and sometimes the names are so long that which-key
cuts the name short and all you see is a bunch of keybindings for seemingly the
same function.
The only remedy I've found is to re-define the keybindings decorating them with descriptions that (hopefully) are easier to understand than the function name. (At least, this way I only have myself to blame if it's a bad description.)
One such keymap that I use somewhat frequently, and where the function names
often confuse me is evil-mc-key-map from evil-mc. The keymap is bound at g .
in evil's normal and visual modes, and it also contains a few bindings using
control (C-) and meta (M-) which I think would be better placed under
sub-keymaps.
I decided to group the "make and go" functions under g . m and the "skip and
go" function under g . s. The rest I'm just giving descriptions. general.el
makes it easy both to overwrite already existing bindings, but adding
descriptions, and to add new ones, all in one call to general-def:
(general-def evil-mc-key-map :states '(normal visual) "g.A" '("make end sel" . evil-mc-make-cursor-in-visual-selection-end) "g.I" '("make beg sel" . evil-mc-make-cursor-in-visual-selection-beg) "g.a" '("make all" . evil-mc-make-all-cursors) "g.q" '("undo all" . evil-mc-undo-all-cursors) "g.u" '("undo last" . evil-mc-undo-last-added-cursor) "g. RET" '("make here" . evil-mc-make-cursor-here) "g.p" '("pause" . evil-mc-pause-cursors) "g.r" '("resume" . evil-mc-resume-cursors) "g.m" '(:ignore t :wk "make & go") "g.m$" '("to last cur" . evil-mc-make-and-goto-last-cursor) "g.m0" '("to first cur" . evil-mc-make-and-goto-first-cursor) "g.mC" '("to prev cur" . evil-mc-make-and-goto-prev-cursor) "g.mc" '("to next cur" . evil-mc-make-and-goto-next-cursor) "g.mh" '("to prev match" . evil-mc-make-and-goto-prev-match) "g.mj" '("to next line" . evil-mc-make-cursor-move-next-line) "g.mk" '("to prev line" . evil-mc-make-cursor-move-prev-line) "g.ml" '("to next match" . evil-mc-make-and-goto-next-match) "g.s" '(:ignore t :wk "skip & go") "g.sC" '("to prev cur" . evil-mc-skip-and-goto-prev-cursor) "g.sc" '("to next cur" . evil-mc-skip-and-goto-next-cursor) "g.sh" '("to prev match" . evil-mc-skip-and-goto-prev-match) "g.sl" '("to next match" . evil-mc-skip-and-goto-next-match))
Finally I want to remove the bindings that weren't overwritten. general.el
makes that easy too with general-undbind:
(general-unbind '(normal visual) evil-mc-key-map "g.$" "g.0" "g. C-n" "g. C-S-n" "g. C-u" "g. C-S-u" "g. C-p" "g. C-r" "g. M-N" "g. M-n" "g.N" "g.O" "g.n" "g.o")
Yes, this is a bit of work, and so far I've only done this for a few keymaps (those containing bindings I use frequently and/or find difficult to remember). So far I've found it worth the cost.
general.el and two ways to define keybindings
When I abandoned spacemacs I really wanted to duplicate its keybindings using
SPC as leader key and per-mode bindings available by pressing ,. I found a
nice setup using general.el in Tianshu Wang's Emacs config. I made only minor
modification and ended up with the following setup.
(use-package general :after (evil evil-easymotion) :config (general-evil-setup) (general-auto-unbind-keys) (general-define-key :states '(normal insert motion visual emacs) :keymaps 'override :prefix-map 'tyrant-map :prefix "SPC" :non-normal-prefix "M-SPC") (general-create-definer mes/tyrant-def :keymaps 'tyrant-map) (mes/tyrant-def "" nil) (general-create-definer mes/despot-def :states '(normal insert motion visual emacs) :keymaps 'override :major-modes t :prefix "," :non-normal-prefix "M-,") (mes/despot-def "" nil) (general-def universal-argument-map "SPC u" 'universal-argument-more))
One slightly surprising thing I found out is that two different ways to define keybindings can be used, one seems to work on both top and mode level, the other only on mode level.
Top-level keybindings (SPC)
At the top-level, i.e. when using mes/tyrant-def, I need to use a cons based
configuration. This is part of my top-level keybindings:
(mes/tyrant-def "SPC" '("M-x" . execute-extended-command) "TAB" '("latest buffer" . mode-line-other-buffer) "!" 'shell-command "/" '("search" . consult-ripgrep) "u" 'universal-argument "b" (cons "bufs" (make-sparse-keymap)) "bb" '("switch" . consult-buffer) "bc" '("close" . kill-this-buffer) "be" '("erase" . erase-buffer) "bs" '("scratch" . scratch-buffer) ;; .... )
When it's done this way which-key picks up the descriptive strings.
It did take me a while to figure out that this config style was necessary. Again Tianshu Wang's Emacs config was what led me right.
Mode-level keybindings (,)
At the mode-level, i.e. using mes/despot-def, I've found that I can, almost
always, define keybindings following the documentation of general.el. Here's the
keybindings I have for nix-mode:
(mes/despot-def nix-mode-map "=" '(:ignore t :wk "format") "=b" '(nix-format-buffer :wk "buffer"))
Just the other day I found that AUCTeX must be doing something with it's keymaps
and I have to use the cons-based configuration style for its keymaps.
More on tree-sitter and consult
Here's a few things that I've gotten help with figuring out during the last few days. Both things are related to my playing with tree-sitter that I've written about earlier, here and here.
You might also be interested in the two repositories where the full code is. (I've linked to the specific commits as of this writing.)
Anonymous nodes and matching in tree-sitter
In the grammar for Cabal I have a rule for sections that like this
sections: $ => repeat1(choice( $.benchmark, $.common, $.executable, $.flag, $.library, $.source_repository, $.test_suite, )),
where each section followed this pattern
benchmark: $ => seq( repeat($.comment), 'benchmark', field('name', $.section_name), field('properties', $.property_block), ),
This made it a little bit difficult to capture the relevant parts of each
section to implement consult-cabal. I thought a pattern like this ought to
work
(cabal (sections (_ _ @type name: (section_name)? @name)))
but it didn't; I got way too many things captured in type. Clearly I had
misunderstood something about the wildcards, or the query syntax. I attempted to
add a field name to the anonymous node, i.e. change the sections rules like this
benchmark: $ => seq( repeat($.comment), field('type', 'benchmark'), field('name', $.section_name), field('properties', $.property_block), ),
It was accepted by tree-sitter generate, but the field type was nowhere to
be found in the parse tree.
Then I changed the query to list the anonymous nodes explicitly, like this
(cabal (sections (_ ["benchmark" "common" "executable" ...] @type name: (section_name)? @name)))
That worked, but listing all the sections like that in the query didn't sit right with me.
Luckily there's a discussions area in tree-sitters GitHub so a fairly short
discussion later I had answers to why my query behaved like it did and a
solution that would allow me to not list all the section types in the query. The
trick is to wrap the string in a call to alias to make it a named node. After
that it works to add a field name to it as well, of course. The section rules
now look like this
benchmark: $ => seq( repeat($.comment), field('type', alias('benchmark', $.section_type)), field('name', $.section_name), field('properties', $.property_block), ),
and the final query looks like this
(cabal (sections (_ type: (section_type) @type name: (section_name)? @name)))
With that in place I could improve on the function that collects all the items
for consult-cabal so it now show the section's type and name instead of the
string representation of the tree-sitter node.
State in a consult source for preview of lines in a buffer
I was struggling with figuring out how to make a good state function in order
to preview the items in consult-cabal. The GitHub repo for consult doesn't
have discussions enabled, but after a discussion in an issue I'd arrived at a
state function that works very well.
The state function makes use of functions in consult and looks like this
(defun consult-cabal--state () "Create a state function for previewing sections." (let ((state (consult--jump-state))) (lambda (action cand) (when cand (let ((pos (get-text-property 0 'section-pos cand))) (funcall state action pos))))))
The trick here was to figure out how the function returned by
consult--jump-state actually works. On the surface it looks like it takes an
action and a candidate, (lambda (action cand) ...). However, the argument
cand shouldn't be the currently selected item, but rather a postion (ideally a
marker), so I had to attach another text property on the items (section-pos,
which is fetched in the inner lambda). This position is then what's passed to
the function returned by consult--jump-state.
In hindsight it seems so easy, but I was struggling with this for an entire evening before finally asking the question the morning after.
Cabal, tree-sitter, and consult
After my last post I thought I'd move on to implement the rest of the functions
in haskell-mode's major mode for Cabal, functions like
haskell-cabal-goto-library-section and
haskell-cabal-goto-executable-section. Then I realised that what I really
want is a way to quickly jump to any section, that is, I want consult-cabal!
What follows is very much a work-in-progress, but hopefully it'll show enough promise.
Listing the sections
As I have a tree-sitter parse tree to hand it is fairly easy to fetch all the
nodes corresponding to sections. Since the last post I've made some
improvements to the parser and now the parse tree looks like this (I can
recommend the function treesit-explore-mode to expore the parse tree, I've
found it invaluable ever since I realised it existed)
(cabal ... (properties ...) (sections (common common (section_name) ...) (library library ...) (executable executable (section_name) ...) ...))
That is, all the sections are children of the node called sections.
The function to use for fetching all the nodes is treesit-query-capture, it
needs a node to start on, which this case should be the full parse tree,
i.e. (treesit-buffer-root-node 'cabal) and a query string. Given the
structure of the parse tree, and that I want to capture all children of
sections, a query string like this one works
"(cabal (sections (_)* @section))"
Finally, by default treesit-query-capture returns a list of tuples of the form
(<capture> . <node>), but in this case I only want the list of nodes, so the
full call will look like this
(treesit-query-capture (treesit-buffer-root-node 'cabal) "(cabal (sections (_)* @section))" nil nil t)
Hooking it up to consult
As I envision adding more things to jump to in the future, I decided to make use
of consult--multi. That in turn means I need to define a "source" for the
sections. After a bit of digging and rummaging in the consult source I put
together this
(defvar consult-cabal--source-section `(:name "Sections" :category location :action ,#'consult-cabal--section-action :items ,#'consult-cabal--section-items) "Definition of source for Cabal sections.")
which means I need two functions, consult-cabal--section-action and
consult-cabal--section-items. I started with the latter.
Getting section nodes as items for consult
It took me a while to work understand how this would ever be able to work. The
function that :items point to must return a list of strings, but how would I
ever be able to use just a string to jump to the correct location?
The solution is in a comment in the documentation of consult--multi:
:items - List of strings to select from or function returning list of strings. Note that the strings can use text properties to carry metadata, which is then available to the :annotate, :action and :state functions.
I'd never come across text properties in Emacs before, so at first I
completely missed those two words. Once I'd looked up the concept in the
documentation everything fell into place. The function
consult-cabal--section-items would simply attach the relevant node as a text
property to the strings in the list.
My current version, obviously a work-in-progress, takes a list of nodes and turns them naïvely into a string and attaches the node. I split it into two functions, like this
(defun consult-cabal--section-to-string (section) "Convert a single SECTION node to a string." (propertize (format "%S" section) :treesit-node section)) (defun consult-cabal--section-items () "Fetch all sections as a list of strings ." (let ((section-nodes (treesit-query-capture (treesit-buffer-root-node 'cabal) "(cabal (sections (_)* @section))" nil nil t))) (mapcar #'consult-cabal--section-to-string section-nodes)))
Implementing the action
The action function is called with the selected item, i.e. with the string and
its properties. That means, to jump to the selected section the function needs
to extract the node property, :treesit-node, and jump to the start of it. the
function to use is get-text-property, and as all characters in the string will
have to property I just picked the first one. The jumping itself I copied from
the navigation functions I'd written before.
(defun consult-cabal--section-action (item) "Go to the section referenced by ITEM." (when-let* ((node (get-text-property 0 :treesit-node item)) (new-pos (treesit-node-start node))) (goto-char new-pos)))
Tying it together with consult--multi
The final function, consult-cabal, looks like this
(defun consult-cabal () "Choose a Cabal construct and jump to it." (interactive) (consult--multi '(consult-cabal--source-section) :sort nil))
Conclusions and where to find the code
The end result works as intended, but it's very rough. I'll try to improve it a bit more. In particular I want
- better strings -
(format "%S" node)is all right to start with, but in the long run I want strings that describe the sections, and - preview as I navigate between items - AFAIU this is what the
:statefield is for, but I still haven't looked into how it works.
The source can be found here.
Making an Emacs major mode for Cabal using tree-sitter
A few days ago I posted on r/haskell that I'm attempting to put together a Cabal grammar for tree-sitter. Some things are still missing, but it covers enough to start doing what I initially intended: experiment with writing an alternative Emacs major mode for Cabal.
The documentation for the tree-sitter integration is very nice, and several of
the major modes already have tree-sitter variants, called X-ts-mode where X
is e.g. python, so putting together the beginning of a major mode wasn't too
much work.
Configuring Emacs
First off I had to make sure the parser for Cabal was installed. The snippet for that looks like this1
(use-package treesit :straight nil :ensure nil :commands (treesit-install-language-grammar) :init (setq treesit-language-source-alist '((cabal . ("https://gitlab.com/magus/tree-sitter-cabal.git")))))
With that in place the parser is installed using M-x
treesit-install-language-grammar and choosing cabal.
After that I removed my configuration for haskell-mode and added the following
snippet to get my own major mode into my setup.
(use-package my-cabal-mode :straight (:type git :repo "git@gitlab.com:magus/my-emacs-pkgs.git" :branch "main" :files (:defaults "my-cabal-mode/*el")))
The major mode and font-locking
The built-in elisp documentation actually has a section on writing a major mode with tree-sitter, so it was easy to get started. Setting up the font-locking took a bit of trial-and-error, but once I had comments looking the way I wanted it was easy to add to the setup. Oh, and yes, there's a section on font-locking with tree-sitter in the documentation too. At the moment it looks like this
(defvar cabal--treesit-font-lock-setting (treesit-font-lock-rules :feature 'comment :language 'cabal '((comment) @font-lock-comment-face) :feature 'cabal-version :language 'cabal '((cabal_version _) @font-lock-constant-face) :feature 'field-name :language 'cabal '((field_name) @font-lock-keyword-face) :feature 'section-name :language 'cabal '((section_name) @font-lock-variable-name-face)) "Tree-sitter font-lock settings.") ;;;###autoload (define-derived-mode my-cabal-mode fundamental-mode "My Cabal" "My mode for Cabal files" (when (treesit-ready-p 'cabal) (treesit-parser-create 'cabal) ;; set up treesit (setq-local treesit-font-lock-feature-list '((comment field-name section-name) (cabal-version) () ())) (setq-local treesit-font-lock-settings cabal--treesit-font-lock-setting) (treesit-major-mode-setup))) ;;;###autoload (add-to-list 'auto-mode-alist '("\\.cabal\\'" . my-cabal-mode))
Navigation
One of the reasons I want to experiment with tree-sitter is to use it for code
navigation. My first attempt is to translate haskell-cabal-section-beginning
(in haskell-mode, the source) to using tree-sitter. First a convenience
function to recognise if a node is a section or not
(defun cabal--node-is-section-p (n) "Predicate to check if treesit node N is a Cabal section." (member (treesit-node-type n) '("benchmark" "common" "executable" "flag" "library" "test_suite")))
That makes it possible to use treesit-parent-until to traverse the nodes until
hitting a section node
(defun cabal-goto-beginning-of-section () "Go to the beginning of the current section." (interactive) (when-let* ((node-at-point (treesit-node-at (point))) (section-node (treesit-parent-until node-at-point #'cabal--node-is-section-p)) (start-pos (treesit-node-start section-node))) (goto-char start-pos)))
And the companion function, to go to the end of a section is very similar
(defun cabal-goto-end-of-section () "Go to the end of the current section." (interactive) (when-let* ((node-at-point (treesit-node-at (point))) (section-node (treesit-parent-until node-at-point #'cabal--node-is-section-p)) (end-pos (treesit-node-end section-node))) (goto-char end-pos)))
Footnotes:
I'm using straight.el and use-package in my setup, but hopefully the
snippets can easily be converted to other ways of configuring Emacs.
Per-project xref history in Emacs
When I write code I jump around in the code quite a bit, as I'm sure many other developers do. The ability to jump to the definition of a function, or a type, is invaluable when trying to understand code. In Emacs the built-in xref package provides the basic functionality for this, with many other packages providing their custom functions for looking up identifiers. This works beautifully except for one thing, there's only one global stack for keeping track of how you've jumped around.
Well, that used to be the case.
As I tend to have multiple projects open at a time I used to find it very
confusing when I pop positions off the xref stack and all of a sudden find
myself in another project. It would be so much nicer to have a per-project
stack.
I've only known of one solution for this, the perspective package, but as I've been building my own Emacs config I wanted to see if there were other options. It turns out there is one (almost) built into Emacs 29.
In Emacs 29 there's built-in support for having per-window xref stacks, and
the way that's done allows one to extend it further. There's now a variable,
xref-history-storage, that controls access to the xref stack. The default is
still a global stack (when the variable is set to #'xref-global-history), but
to get per-window stacks one sets it to #'xref-window-local-history.
After finding this out I thought I'd try to write my own, implementing
per-project xref stacks (for projectile).
The function should take one optional argument, new-value, if it's provided
the stack should be updated and if not, it should be returned. That is,
something like this
(defun projectile-param-xref-history (&optional new-value) "Return project-local xref history for the current projectile. Override existing value with NEW-VALUE if it's set." (if new-value (projectile-param-set-parameter 'xref--history new-value) (or (projectile-param-get-parameter 'xref--history) (projectile-param-set-parameter 'xref--history (xref--make-xref-history)))))
Now I only had to write the two functions projectile-param-get-parameter and
projectile-param-set-parameter. I thought a rather straight forward option
would be to use a hashtable and store values under a tuple comprising the
project name and the parameter passed in.
(defvar projectile-params--store (make-hash-table :test 'equal) "The store of project parameters.") (defun projectile-param-get-parameter (param) "Return project parameter PARAM, or nil if unset." (let ((key (cons (projectile-project-name) param))) (gethash key projectile-params--store nil))) (defun projectile-param-set-parameter (param value) "Set the project parameter PARAM to VALUE." (let ((key (cons (projectile-project-name) param))) (puthash key value projectile-params--store)) value)
Then I tried it out by setting xref-history-storage
(setq xref-history-storage #'projectile-param-xref-history)
and so far it's been working well.
The full code is here.
Annotate projects in Emacs
Every now and then I've wished to write comments on files in a project, but I've
never found a good way to do that. annotate.el and org-annotate-file both
collect annotations in a central place (in my $HOME), while marginalia puts
annotations in files next to the source files but in a format that's rather
cryptic and tends to be messed up when attached to multiple lines. None of them
is ideal, I'd like the format to be org-mode, but not in a central file. At the
same time having one annotation file per source file is simply too much.
I tried wrapping org-annotate-file, setting org-annotate-file-storage-file
and taking advantage of elisp's dynamic binding. However, it opens the
annotation file in the current window, and I'd really like to split the window
and open the annotations the right. Rather than trying to sort of "work it out
backwards" I decided to write a small package and use as much of the
functionality in org-annotate-file.el as possible.
First off I decided that I want the annotation file to be called
projectile-annotations.org.
(defvar org-projectile-annotate-file-name "projectile-annotations.org" "The name of the file to store project annotations.")
Then I wanted a slightly modified version of org-annotate-file-show-section, I
wanted it to respect the root of the project.
(defun org-projectile-annotate--file-show-section (storage-file) "Add or show annotation entry in STORAGE-FILE and return the buffer." ;; modified version of org-annotate-file-show-section (let* ((proj-root (projectile-project-root)) (filename (file-relative-name buffer-file-name proj-root)) (line (buffer-substring-no-properties (point-at-bol) (point-at-eol))) (annotation-buffer (find-file-noselect storage-file))) (with-current-buffer annotation-buffer (org-annotate-file-annotate filename line)) annotation-buffer))
The main function can then simply work out where the file with annotations
should be located and call org-projectile-annotate--file-show-section.
(defun org-projectile-annotate () (interactive) (let ((annot-fn (file-name-concat (projectile-project-root) org-projectile-annotate-file-name))) (set-window-buffer (split-window-right) (org-projectile-annotate--file-show-section annot-fn))))
When testing it all out I noticed that org-store-link makes a link with a
search text. In my case it would be much better to have links with line numbers.
I found there's a hook to modify the behaviour of org-store-link,
org-create-file-search-functions. So I wrote a function to get the kind of
links I want, but only when the project annotation file is open in a buffer.
(defun org-projectile-annotate-file-search-func () "A function returning the current line number when called in a project while the project annotation file is open. This function is designed for use in the hook 'org-create-file-search-functions'. It changes the behaviour of 'org-store-link' so it constructs a link with a line number instead of a search string." ;; TODO: find a way to make the link description nicer (when (and (projectile-project-p) (get-buffer-window org-projectile-annotate-file-name)) (number-to-string (line-number-at-pos))))
That's it, now I only have to wait until the next time I want to comment on a project to see if it improves my way of working.
Playing with setting up Emacs
TL;DR: I've put together a small-ish Emacs configuration that I call MES. Hopefully it can be of use to someone out there.
My Emacs Setup - MES
The other day I started watching some videos in the Emacs From Scratch series from System Crafters. It looked like something that could be fun to play with so over the last couple of days I've been tinkering with putting together the beginnings of a configuration.
During the process I realised just how much work it'd be to put together something that comes close to the polish of Spacemacs, so I've currently no intention of actually using MES myself. It was fun though, and maybe it can serve as inspiration (or as a deterrent) for someone else.
The major parts are
Power-mode in Spacemacs
I just found the Power Mode for Emacs. If you want to try it out in Spacemacs
you can make sure that your ~/.spacemacs contains the following
dotspacemacs-additional-packages '( ... (power-mode :location (recipe :fetcher github :repo "elizagamedev/power-mode.el")) )
After a restart Power Mode can be turned on using SPC SPC power-mode.
Unfortunately I found that it slows down rendering so badly that Emacs isn't keeping up with my typing. Even though I removed it right away again it was fun to try it out, and I did learn how to add package to Spacemacs that aren't on MELPA.
A useful resource is this reference on the recipe format.
Comments and org-static-blog
I'm using org-static-blog to generate the contents of this site. So far I'm very happy with it, but I've gotten a few emails from readers who've wanted to comment on something I've written and they always point out that it's not easy to do. It's actually not a coincidence that it's a bit difficult!
Yesterday I came up with a way that might make is slightly easier without involving JavaScript from a 3rd party. By making use of the built-in support for adding HTML code for comments. One slight limitation is that it's a single variable holding the code, and I'd really like to allow for both
- using a link to a discussion site, e.g. reddit, as well as
- my email address
As the comment support in org-static-blog comes in the form of a single variable
this seems a bit difficult to accomplish. However, it isn't difficult at all to
do in elisp due to the power of advice-add.
By using the following advice on org-static-blog-publish-file
(advice-add 'org-static-blog-publish-file :around (lambda (orig-fn filename &rest args) (let* ((comments-url (with-temp-buffer (insert-file-contents filename) (or (cadar (org-collect-keywords '("commentsurl"))) my-blog-default-comments-url))) (org-static-blog-post-comments (concat "Comment <a href=" comments-url ">here</a>."))) (apply orig-fn filename args))))
and defining my-blog-default-comments-url to a mailto:... URL I get a link
to use for commenting by either
- set
commentsurlto point to discussion about the post on reddit, or - not set
commentsurlat all and get themailto:...URL.
If you look at my previous post you see the result of the former, and if you look below you see the result of the latter.
Keeping Projectile's cache tidy
A while back I added a function to find all projects recursively from a
directory and add them to Projectile's cache (see the Populating Projectile's
cache). Since then I've just made a tiny change to also include containing a
.projectile file.
(defun projectile-extra-add-projects-in-subfolders (projects-root) (interactive (list (read-directory-name "Add to known projects: "))) (message "Searching for projects in %s..." projects-root) (let* ((proj-rx (rx (and line-start ?. (or "projectile" "git") line-end))) (dirs (seq-map 'file-name-directory (directory-files-recursively projects-root proj-rx t)))) (seq-do 'projectile-add-known-project dirs) (message "Added %d projects" (length dirs))))
Since then I've also found a need for tidying the cache, in my casse that means removing entries in the cache that no longer exist on disk. I didn't find a function for it, so I wrote one.
(defun projectile-extra-tidy-projects () (interactive) (let ((missing-dirs (seq-remove 'file-directory-p projectile-known-projects))) (seq-do 'projectile-remove-known-project missing-dirs) (message "Tidied %d projects" (length missing-dirs))))
Trimming newline on code block variable
Today I found ob-http and decided to try it out a little. I quickly ran into a problem of a trailing newline. Basically I tried to do something like this:
#+begin_src http :select .id :cache yes POST /foo Content-Type: application/json { "foo": "toto", "bar": "tata" } #+end_src #+begin_example 48722051-f81b-433f-acb4-a65d961ec841 #+end_example #+begin_src http POST /foo/${id}/fix #+end_src
The trailing newline messes up the URL though, and the second code block fails.
I found two ways to deal with it, using a table and using org-sbe
Using a table
#+begin_src http :select .id :cache yes :results table POST /foo Content-Type: application/json { "foo": "toto", "bar": "tata" } #+end_src #+begin_example | 48722051-f81b-433f-acb4-a65d961ec841 | #+end_example #+begin_src http POST /foo/${id}/fix #+end_src
Using org-sbe
#+begin_src http :select .id :cache yes POST /foo Content-Type: application/json { "foo": "toto", "bar": "tata" } #+end_src #+begin_example 48722051-f81b-433f-acb4-a65d961ec841 #+end_example #+begin_src http POST /foo/${id}/fix #+end_src
Magit/forge and self-hosted GitLab
As I found the documentation for adding a self-hosted instance of GitLab to to magit/forge a bit difficult, I thought I'd write a note for my future self (and anyone else who might find it useful).
First put the following in `~/.gitconfig`
[gitlab "gitlab.private.com/api/v4"] user = my.username
Then create an access token on GitLab. I ticked api and write_repository,
which seems to work fine so far. Put the token in ~/.authinfo.gpg
machine gitlab.private.com/api/v4 login my.user^forge password <token>
(Remember that a newline is needed at the end of the file.)
Finally, add the GitLab instance to 'forge-alist
(setq forge-alist '(("gitlab.private.com" "gitlab.private.com/api/v4" "gitlab.private.com" forge-gitlab-repository) ("github.com" "api.github.com" "github.com" forge-github-repository) ("gitlab.com" "gitlab.com/api/v4" "gitlab.com" forge-gitlab-repository)) )
That's it!
Keeping todo items in org-roam v2
Org-roam v2 has been released and yes, it broke my config a bit. Unfortunately the v1-to-v2 upgrade wizard didn't work for me. I realized later that it might have been due to the roam-related functions I'd hooked into `'before-save-hook`. I didn't think about it until I'd already manually touched up almost all my files (there aren't that many) so I can't say anything for sure. However, I think it might be a good idea to keep hooks in mind if one runs into issues with upgrading.
The majority of the time I didn't spend on my notes though, but on the setup I've written about in an earlier post, Keeping todo items in org-roam. Due to some of the changes in v2, changes that I think make org-roam slightly more "org-y", that setup needed a bit of love.
The basis is still the same 4 functions I described in that post, only the details had to be changed.
I hope the following is useful, and as always I'm always happy to receive commends and suggestions for improvements.
Some tag helpers
The very handy functions for extracting tags as lists seem to be gone, in their
place I found org-roam-{get,set}-keyword. Using these I wrote three wrappers
that allow slightly nicer handling of tags.
(defun roam-extra:get-filetags () (split-string (or (org-roam-get-keyword "filetags") ""))) (defun roam-extra:add-filetag (tag) (let* ((new-tags (cons tag (roam-extra:get-filetags))) (new-tags-str (combine-and-quote-strings new-tags))) (org-roam-set-keyword "filetags" new-tags-str))) (defun roam-extra:del-filetag (tag) (let* ((new-tags (seq-difference (roam-extra:get-filetags) `(,tag))) (new-tags-str (combine-and-quote-strings new-tags))) (org-roam-set-keyword "filetags" new-tags-str)))
The layer
roam-extra:todo-p needed no changes at all. I'm including it here only for
easy reference.
(defun roam-extra:todo-p () "Return non-nil if current buffer has any TODO entry. TODO entries marked as done are ignored, meaning the this function returns nil if current buffer contains only completed tasks." (org-element-map (org-element-parse-buffer 'headline) 'headline (lambda (h) (eq (org-element-property :todo-type h) 'todo)) nil 'first-match))
As pretty much all functions I used in the old version of
roam-extra:update-todo-tag are gone I took the opportunity to rework it
completely. I think it ended up being slightly simpler. I suspect the the use of
org-with-point-at 1 ... is unnecessary, but I haven't tested it yet so I'm
leaving it in for now.
(defun roam-extra:update-todo-tag () "Update TODO tag in the current buffer." (when (and (not (active-minibuffer-window)) (org-roam-file-p)) (org-with-point-at 1 (let* ((tags (roam-extra:get-filetags)) (is-todo (roam-extra:todo-p))) (cond ((and is-todo (not (seq-contains-p tags "todo"))) (roam-extra:add-filetag "todo")) ((and (not is-todo) (seq-contains-p tags "todo")) (roam-extra:del-filetag "todo")))))))
In the previous version roam-extra:todo-files was built using an SQL query.
That felt a little brittle to me, so despite that my original inspiration
contains an updated SQL query I decided to go the route of using the org-roam
API instead. The function org-roam-node-list makes it easy to get all nodes
and then finding the files is just a matter of using seq-filter and seq-map.
Now that headings may be nodes, and that heading-based nodes seem to inherit the
top-level tags, a file may appear more than once, hence the call to seq-unique
at the end.
Based on what I've seen V2 appears less eager to sync the DB, so to make sure all nodes are up-to-date it's best to start off with forcing a sync.
(defun roam-extra:todo-files () "Return a list of roam files containing todo tag." (org-roam-db-sync) (let ((todo-nodes (seq-filter (lambda (n) (seq-contains-p (org-roam-node-tags n) "todo")) (org-roam-node-list)))) (seq-uniq (seq-map #'org-roam-node-file todo-nodes))))
With that in place it turns out that also roam-extra:update-todo-files worked
without any changes. I'm including it here for easy reference as well.
(defun roam-extra:update-todo-files (&rest _) "Update the value of `org-agenda-files'." (setq org-agenda-files (roam-extra:todo-files)))
Hooking it up
The variable org-roam-file-setup-hook is gone, so the the more general
find-file-hook will have to be used instead.
(add-hook 'find-file-hook #'roam-extra:update-todo-tag) (add-hook 'before-save-hook #'roam-extra:update-todo-tag) (advice-add 'org-agenda :before #'roam-extra:update-todo-files)
Todo items in org-roam, an update
I got an email from Mr Z with a nice modification to the code in my post on keeping todo items in org-roam.
He already had a bunch of agenda files that he wanted to keep using (I had so few of them that I'd simply converted them to roam files). Here's the solution he shared with me:
(defvar roam-extra-original-org-agenda-files nil "Original value of `org-agenda-files'.") (defun roam-extra:update-todo-files (&rest _) "Update the value of `org-agenda-files'." (unless roam-extra-original-org-agenda-files (setq roam-extra-original-org-agenda-files org-agenda-files)) (setq org-agenda-files (append roam-extra-original-org-agenda-files (roam-extra:todo-files))))
It's a rather nice modification I think. Thanks to Mr Z for agreeing to let me share it here.
Keeping todo items in org-roam
A while ago I made an attempt to improve my work habits by keeping a document
with TODO items. It lasted only for a while, and I've since had the intention to
make another attempt. Since then I've started using org-roam and I've managed to
create a habit of writing daily journal notes using org-roam's daily-notes. A
few times I've thought that it might fit me well to put TODO items in the notes,
but that would mean that I'd have to somehow keep track of them. At first I
manually added a tag to each journal fily containing a TODO item. That didn't
work very well at all, which should have been obvious up front. Then I added the
folders where I keep roam files and journals to org-agenda-files, that worked
a lot better. I'd still be using that, even if I expected it to slow down
considerably as the number of files grow, but then I found a post on dynamic and
fast agenda with org-roam.
I adjusted it slightly to fit my own setup a bit better, i.e. I made a Spacemacs
layer, roam-extra, I use the tag todo, and I use a different hook to get the
tag added on opening an org-roam file.
The layer consists of a single file, layers/roam-extra/funcs.el. In it I
define 4 functions (they are pretty much copies of the functions in the post
linked above):
roam-extra:todo-p- returns non-nilif the current current buffer contains a TODO item.roam-extra:update-todo-tag- updates the tags of the current buffer to reflect the presence of TODO items, i.e. ensure the the tagtodois present iff there's a TODO item.roam-extra:todo-files- uses the org-roam DB to return a list of all files containing the tagtodo.roam-extra:update-todo-files- adjusts'org-agenda-filesto contain only the files with TODO items.
I've put the full contents of the file at the end of the post.
To ensure that the todo tag is correct in all org-mode files I've added
roam-extra:update-todo-tag to hooks that are invoked on opening an org-ram
file and when saving a file. (I would love to find a more specialise hook than
before-save-hook, but it works for now.)
(add-hook 'org-roam-file-setup-hook #'roam-extra:update-todo-tag) (add-hook 'before-save-hook #'roam-extra:update-todo-tag)
To ensure that the list of files with TODO items is kept up to date when I open
I also wrap org-agenda in an advice so roam-extra:update-todo-files is
called prior to the agenda being opened.
(advice-add 'org-agenda :before #'roam-extra:update-todo-files)
The layer, layers/roam-extra/funcs.el
(defun roam-extra:todo-p () "Return non-nil if current buffer has any TODO entry. TODO entries marked as done are ignored, meaning the this function returns nil if current buffer contains only completed tasks." (org-element-map (org-element-parse-buffer 'headline) 'headline (lambda (h) (eq (org-element-property :todo-type h) 'todo)) nil 'first-match)) (defun roam-extra:update-todo-tag () "Update TODO tag in the current buffer." (when (and (not (active-minibuffer-window)) (org-roam--org-file-p buffer-file-name)) (let* ((file (buffer-file-name (buffer-base-buffer))) (all-tags (org-roam--extract-tags file)) (prop-tags (org-roam--extract-tags-prop file)) (tags prop-tags)) (if (roam-extra:todo-p) (setq tags (seq-uniq (cons "todo" tags))) (setq tags (remove "todo" tags))) (unless (equal prop-tags tags) (org-roam--set-global-prop "roam_tags" (combine-and-quote-strings tags)))))) (defun roam-extra:todo-files () "Return a list of note files containing todo tag." (seq-map #'car (org-roam-db-query [:select file :from tags :where (like tags (quote "%\"todo\"%"))]))) (defun roam-extra:update-todo-files (&rest _) "Update the value of `org-agenda-files'." (setq org-agenda-files (roam-extra:todo-files)))
Flycheck and HLS
I've been using LSP for most programming languages for a while now. HLS is
really very good now, but I've found that it doesn't warn on quite all things
I'd like it to so I find myself having to swap between the 'lsp and
'haskell-ghc checkers. However, since flycheck supports chaining checkers I
thought there must be a way to have both checkers active at the same time.
The naive approach didn't work due to load order of things in Spacemacs so I had to experiment a bit to find something that works.
The first issue was to make sure that HLS is available at all. I use shell.nix
together with direnv extensively and I had noticed that lsp-mode tried to load
HLS before direnv had put it in the $PATH. I think the
'lsp-beforeinitialize-hook is the hook to use for this:
(add-hook 'lsp-before-initialize-hook #'direnv-update-environment))
I made a several attempt to chain the checkers but kept on getting
errors due to the 'lsp checker not being defined yet. Another problem
I ran into was that the checkers were chained too late, resulting in
having to manually run flycheck-buffer on the first file I opened.
(Deferred loading is a brilliant thing, but make some things really
difficult to debug.) After quite a bit of experimenting and reading the
description of various hooks I did find something that works:
(with-eval-after-load 'lsp-mode (defun magthe:lsp-next-checker () (flycheck-add-next-checker 'lsp '(warning . haskell-ghc))) (add-hook 'lsp-lsp-haskell-after-open-hook #'magthe:lsp-next-checker))
Of course I have no idea if this is the easiest or most elegant solution but it does work for my testcases:
- Open a file in a project,
SPC p l- choose project - choose a Haskell file. - Open a project,
SPC p lfollowed byC-d, and then open a Haskell file.
Suggestions for improvements are more than welcome, of course.
Better Nix setup for Spacemacs
In an earlier post I documented my setup for getting Spacemacs/Emacs to work with Nix. I've since found a much more elegant solution based on
- direnv, and
- emacs-direnv
No more Emacs packages for Nix and no need to defining functions that wrap
executables in an invocation of nix-shell.
There's a nice bonus too, with this setup I don't need to run nix-shell, which
always drops me at a bash prompt, instead I get a working setup in my shell of
choice.
Setting up direnv
The steps for setting up direnv depends a bit on your setup, but luckily I
found the official instructions for installing direnv to be very clear and
easy to follow. There's not much I can add to that.
Setting up Spacemacs
Since emacs-direnv isn't included by default in Spacemacs I needed to do a bit
of setup. I opted to create a layer for it, rather than just drop it in the list
dotspacemacs-additional-packages. Yes, a little more complicated, but not
difficult and I nurture an intention of submitting the layer for inclusion in
Spacemacs itself at some point. I'll see where that goes.
For now, I put the following in the file
~/.emacs.d/private/layers/direnv/packages.el:
(defconst direnv-packages '(direnv)) (defun direnv/init-direnv () (use-package direnv :init (direnv-mode)))
Setting up the project folders
In each project folder I then add the file .envrc containing a single line:
use_nix
Then I either run direnv allow from the command line, or run the
function direnv-allow after opening the folder in Emacs.
Using it
It's as simple as moving into the folder in a shell – all required envvars are set up on entry and unset on exit.
In Emacs it's just as simple, just open a file in a project and the envvars are set. When switching to a buffer outside the project the envvars are unset.
There is only one little caveat, nix-build doesn't work inside a Nix shell. I
found out that running
IN_NIX_SHELL= nix-build
does work though.
Nix setup for Spacemacs
Edit 2020-06-22: I've since found a better setup for this.
When using ghcide and LSP, as I wrote about in my post on Haskell, ghcide, and
Spacemacs, I found myself ending up recompiling a little too often. This pushed
me to finally start looking at Nix. After a bit of a fight I managed to
get ghcide from Nix,
which brought me the issue of setting up Spacemacs. Inspired by a gist from
Samuel Evans-Powell and a guide to setting up an environment for Reflex by
Thales Macedo Garitezi I ended up with the following setup:
(defun dotspacemacs/layers () (setq-default ... dotspacemacs-additional-packages '( nix-sandbox nix-haskell-mode ... ) ... ))
(defun dotspacemacs/user-config () ... (add-hook 'haskell-mode-hook #'lsp) (add-hook 'haskell-mode-hook 'nix-haskell-mode) (add-hook 'haskell-mode-hook (lambda () (setq-local flycheck-executable-find (lambda (cmd) (nix-executable-find (nix-current-sandbox) cmd))) (setq-local flycheck-command-wrapper-function (lambda (argv) (apply 'nix-shell-command (nix-current-sandbox) argv))) (setq-local haskell-process-wrapper-function (lambda (argv) (apply 'nix-shell-command (nix-current-sandbox) argv))) (setq-local lsp-haskell-process-wrapper-function (lambda (argv) `("nix-shell" "-I" "." "--command" "ghcide --lsp" ,(nix-current-sandbox)))))) (add-hook 'haskell-mode-hook (lambda () (flycheck-add-next-checker 'lsp-ui '(warning . haskell-stack-ghc)))) ... )
It seems to work, but please let me know if you have suggestions for improvements.
Populating Projectile's cache
As I track the develop branch of Spacemacs I occasionally clean out my cache of projects known to Projectile. Every time it takes a while before I'm back at a stage where I very rarely have to visit something that isn't already in the cache.
However, today I found the function projectile-add-known-project, which
prompted me to write the following function that'll help me quickly re-building
the cache the next time I need to reset Spacemacs to a known state again.
(defun projectile-extra-add-projects-in-subfolders (projects-root) (interactive (list (read-directory-name "Add to known projects: "))) (message "Searching for projects in %s..." projects-root) (let ((dirs (seq-map 'file-name-directory (directory-files-recursively projects-root "^.git$" t)))) (seq-do 'projectile-add-known-project dirs) (message "Added %d projects" (length dirs))))
Ditaa in Org mode
Just found out that Emacs ships with Babel support for ditaa (yes, I'm late to the party).
Sweet! That is yet another argument for converting all our README.md into
README.org at work.
 \
\
The changes I made to my Spacemacs config are
(defun dotspacemacs/user-config () ... (with-eval-after-load 'org ... (add-to-list 'org-babel-load-languages '(ditaa . t)) (setq org-ditaa-jar-path "/usr/share/java/ditaa/ditaa-0.11.jar")) ...)
Haskell, ghcide, and Spacemacs
The other day I read Chris Penner's post on Haskell IDE Support and thought I'd make an attempt to use it with Spacemacs.
After running stack build hie-bios ghcide haskell-lsp --copy-compiler-tool I
had a look at the instructions on using haskell-ide-engine with Spacemacs.
After a bit of trial and error I came up with these changes to my
~/.spacemacs:
(defun dotspacemacs/layers () (setq-default dotspacemacs-configuration-layers '( ... lsp (haskell :variables haskell-completion-backend 'lsp ) ...) ) )
(defun dotspacemacs/user-config () (setq lsp-haskell-process-args-hie '("exec" "ghcide" "--" "--lsp") lsp-haskell-process-path-hie "stack" lsp-haskell-process-wrapper-function (lambda (argv) (cons (car argv) (cddr argv))) ) (add-hook 'haskell-mode-hook #'lsp))
The slightly weird looking lsp-haskell-process-wrapper-function is removing
the pesky --lsp inserted by this line.
That seems to work. Though I have to say I'm not ready to switch from intero just yet. Two things in particular didn't work with =ghcide=/LSP:
- Switching from one the
Main.hsin one executable to theMain.hsof another executable in the same project didn't work as expected – I had hints and types in the first, but nothing in the second. - Jump to the definition of a function defined in the package didn't work – I'm not willing to use GNU GLOBAL or some other source tagging system.
Some OrgMode stuff
The last few days I've watched Rainer König's OrgMode videos. It's resulted in a few new settings that makes Org a little more useful.
| Variable | Value | Description |
|---|---|---|
calendar-week-start-day |
1 |
Weeks start on Monday! |
org-modules (list) |
org-habit |
Support for tracking habits |
org-modules (list) |
org-id |
Improved support for ID property |
org-agenda-start-on-weekday |
1 |
Weeks start on Monday, again! |
org-log-into-drawer |
t |
Put notes (logs) into a drawer |
org-enforce-todo-checkbox-dependencies |
t |
Checkboxes must be checked before a TODO can become DONE |
org-id-link-to-org-use-id |
t |
Prefer use of ID property for links |
TIL: prompt matters to org-mode
A workmate just embellished some shell code blocks I'd put in a shared org-mode
file with :session s. When I tried to run the blocks with sessions my emacs
just froze up though. I found a post on the emacs StackExchange that offered a
possible cause for it: the prompt.
I'm using bash-it so my prompt is rather far from the default.
After inspecting the session buffer simply added the following to my ~/.bashrc
if [[ ${TERM} == "dumb" ]]; then export BASH_IT_THEME='standard' else export BASH_IT_THEME='simple' fi
and now I can finally run shell code blocks in sessions.
A missing piece in my Emacs/Spacemacs setup for Haskell development
With the help of a work mate I've finally found this gem that's been missing from my Spacemacs setup
(with-eval-after-load 'intero (flycheck-add-next-checker 'intero '(warning . haskell-hlint)) (flycheck-add-next-checker 'intero '(warning . haskell-stack-ghc)))
QuickCheck on a REST API
Since I'm working with web stuff nowadays I thought I'd play a little with translating my old post on using QuickCheck to test C APIs to the web.
The goal and how to reach it
I want to use QuickCheck to test a REST API, just like in the case of the C API the idea is to
- generate a sequence of API calls (a program), then
- run the sequence against a model, as well as
- run the sequence against the web service, and finally
- compare the resulting model against reality.
The REST API
I'll use a small web service I'm working on, and then concentrate on only a small part of the API to begin with.
The parts of the API I'll use for the programs at this stage are
| Method | Route | Example in | Example out |
|---|---|---|---|
POST |
/users |
{"userId": 0, "userName": "Yogi Berra"} |
{"userId": 42, "userName": "Yogi Berra"} |
DELETE |
/users/:id |
The following API calls will also be used, but not in the programs
| Method | Route | Example in | Example out |
|---|---|---|---|
GET |
/users |
[0,3,7] |
|
GET |
/users/:id |
{"userId": 42, "userName": "Yogi Berra"} |
|
POST |
/reset |
Representing API calls
Given the information about the API above it seems the following is enough to represent the two calls of interest together with a constructor representing the end of a program
data ApiCall = AddUser Text | DeleteUser Int | EndProgram deriving (Show)
and a program is just a sequence of calls, so list of ApiCall will do.
However, since I want to generate sequences of calls, i.e. implement
Arbitrary, I'll wrap it in a newtype
newtype Program = Prog [ApiCall]
Running against a model (simulation)
First of all I need to decide what model to use. Based on the part of the API
I'm using I'll use an ordinary dictionary of Int and Text
type Model = M.Map Int Text
Simulating execution of a program is simulating each call against a model that's updated with each step. I expect the final model to correspond to the state of the real service after the program is run for real. The simulation begins with an empty dictionary.
simulateProgram :: Program -> Model simulateProgram (Prog cs) = foldl simulateCall M.empty cs
The simulation of the API calls must then be a function taking a model and a call, returning an updated model
simulateCall :: Model -> ApiCall -> Model simulateCall m (AddUser t) = M.insert k t m where k = succ $ foldl max 0 (M.keys m) simulateCall m (DeleteUser k) = M.delete k m simulateCall m EndProgram = m
Here I have to make a few assumptions. First, I assume the indeces for the users
start on 1. Second, that the next index used always is the successor of
highest currently used index. We'll see how well this holds up to reality later
on.
Running against the web service
Running the program against the actual web service follows the same pattern, but
here I'm dealing with the real world, so it's a little more messy, i.e. IO is
involved. First the running of a single call
runCall :: Manager -> ApiCall -> IO () runCall mgr (AddUser t) = do ireq <- parseRequest "POST http://localhost:3000/users" let req = ireq { requestBody = RequestBodyLBS (encode $ User 0 t)} resp <- httpLbs req mgr guard (status201 == responseStatus resp) runCall mgr (DeleteUser k) = do req <- parseRequest $ "DELETE http://localhost:3000/users/" ++ show k resp <- httpNoBody req mgr guard (status200 == responseStatus resp) runCall _ EndProgram = return ()
The running of a program is slightly more involved. Of course I have to set up
the Manager needed for the HTTP calls, but I also need to
- ensure that the web service is in a well-known state before starting, and
- extract the state of the web service after running the program, so I can compare it to the model
runProgram :: Program -> IO Model runProgram (Prog cs) = do mgr <- newManager defaultManagerSettings resetReq <- parseRequest "POST http://localhost:3000/reset" httpNoBody resetReq mgr mapM_ (runCall mgr) cs model <- extractModel mgr return model
The call to POST /reset resets the web service. I would have liked to simply
restart the service completely, but I failed in automating it. I think I'll have
to take a closer look at the implementation of scotty to find a way.
Extracting the web service state and packaging it in a Model is a matter of
calling GET /users and then repeatedly calling GET /users/:id with each id
gotten from the first call
extractModel :: Manager -> IO Model extractModel mgr = do req <- parseRequest "http://localhost:3000/users" resp <- httpLbs req mgr let (Just ids) = decode (responseBody resp) :: Maybe [Int] users <- forM ids $ \ id -> do req <- parseRequest $ "http://localhost:3000/users/" ++ show id resp <- httpLbs req mgr let (Just (user:_)) = decode (responseBody resp) :: Maybe [User] return user return $ foldl (\ map (User id name) -> M.insert id name map) M.empty users
Generating programs
My approach to generating a program is based on the idea that given a certain
state there is only a limited number of possible calls that make sense. Given a
model m it makes sense to make one of the following calls:
- add a new user
- delete an existing user
- end the program
Based on this writing genProgram is rather straight forward
genProgram :: Gen Program genProgram = Prog <$> go M.empty where possibleAddUser _ = [AddUser <$> arbitrary] possibleDeleteUser m = map (return . DeleteUser) (M.keys m) possibleEndProgram _ = [return EndProgram] go m = do let possibles = possibleDeleteUser m ++ possibleAddUser m ++ possibleEndProgram m s <- oneof possibles let m' = simulateCall m s case s of EndProgram -> return [] _ -> (s:) <$> go m'
Armed with that the Arbitrary instance for Program can be implemented as1
instance Arbitrary Program where arbitrary = genProgram shrink p = []
The property of an API
The steps in the first section can be used as a recipe for writing the property
prop_progCorrectness :: Program -> Property prop_progCorrectness program = monadicIO $ do let simulatedModel = simulateProgram program runModel <- run $ runProgram program assert $ simulatedModel == runModel
What next?
There are some improvements that I'd like to make:
- Make the generation of
Programbetter in the sense that the programs become longer. I think this is important as I start tackling larger APIs. - Write an implementation of
shrinkforProgram. With longer programs it's of course more important to actually implementshrink.
I'd love to hear if others are using QuickCheck to test REST APIs in some way,
if anyone has suggestions for improvements, and of course ideas for how to
implement shrink in a nice way.
Footnotes:
Yes, I completely skip the issue of shrinking programs at this point. This is OK at this point though, because the generated =Programs=s do end up to be very short indeed.