Posts tagged "tagless_final":
Architecture of a service
Early this summer it was finally time to put this one service I've been working on into our sandbox environment. It's been running without hickups so last week I turned it on for production as well. In this post I thought I'd document the how and why of the service in the hope that someone will find it useful.
The service functions as an interface to external SMS-sending services, offering a single place to change if we find that we are unhappy with the service we're using.1 This service replaces an older one, written in Ruby and no one really dares touch it. Hopefully the Haskell version will prove to be a joy to work with over time.
Overview of the architecture
The service is split into two parts, one web server using scotty, and streaming data processing using conduit. Persistent storage is provided by a PostgreSQL database. The general idea is that events are picked up from the database, acted upon, which in turn results in other events which written to the database. Those are then picked up and round and round we go. The web service accepts requests, turns them into events and writes the to the database.
Hopefully this crude diagram clarifies it somewhat.
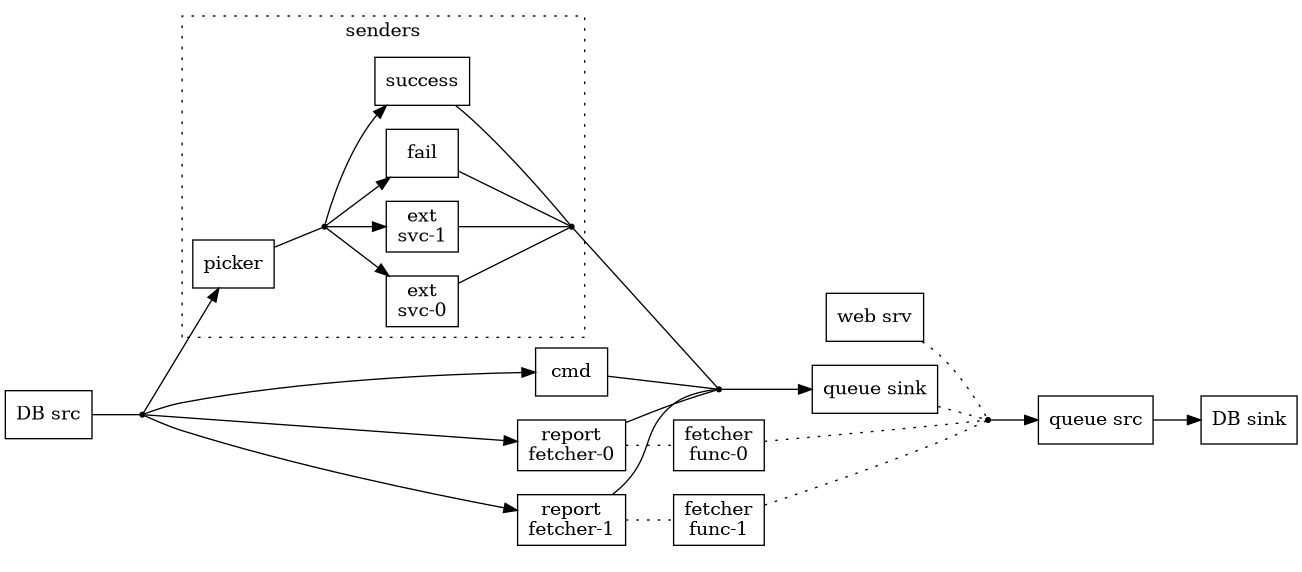
There are a few things that might need some explanation
In the past we've wanted to have the option to use multiple external SMS services at the same time. One is randomly chosen as the request comes in. There's also a possibility to configure the frequency for each external service.
Picker implements the random picking and I've written about that earlier in Choosing a conduit randomly.
Success and fail are dummy senders. They don't actually send anything, and the former succeeds at it while the latter fails. I found them useful for manual testing.
Successfully sending off a request to an external SMS service, getting status 200 back, doesn't actually mean that the SMS has been sent, or even that it ever will be. Due to the nature of SMS messaging there are no guarantees of timeliness at all. Since we are interested in finding out whether an SMS actually is sent a delayed action is scheduled, which will fetch the status of a sent SMS after a certain time (currently 2 minutes). If an SMS hasn't been sent after that time it might as well never be – it's too slow for our end-users.
This is what report-fetcher and fetcher-func do.
- The queue sink and queue src are actually
sourceTQueueandsinkTQueue. Splitting the stream like that makes it trivial to push in events by usingwriteTQueue. - I use
sequenceConduitsin order to send a single event to multiple =Conduit=s and then combine all their results back into a single stream. The ease with which this can be done in conduit is one of the main reasons why I choose to use it.2
Effects and tests
I started out writing everything based on a type like ReaderT <my cfg type> IO
and using liftIO for effects that needed lifting. This worked nicely while I
was setting up the basic structure of the service, but as soon as I hooked in
the database I really wanted to do some testing also of the effectful code.
After reading Introduction to Tagless Final and The ReaderT Design Patter, playing a bit with both approaches, and writing Tagless final and Scotty and The ReaderT design pattern or tagless final?, I finally chose to go down the route of tagless final. There's no strong reason for that decision, maybe it was just because I read about it first and found it very easy to move in that direction in small steps.
There's a split between property tests and unit tests:
- Data types, their monad instances (like JSON (de-)serialisation), pure functions and a few effects are tested using properties. I'm using QuickCheck for that. I've since looked a little closer at hedgehog and if I were to do a major overhaul of the property tests I might be tempted to rewrite them using that library instead.
- Most of the =Conduit=s are tested using HUnit.
Configuration
The service will be run in a container and we try to follow the 12-factor app rules, where the third one says that configuration should be stored in the environment. All previous Haskell projects I've worked on have been command line tools were configuration is done (mostly) using command line argument. For that I usually use optparse-applicative, but it's not applicable in this setting.
After a bit of searching on hackage I settled on etc. It turned out to be nice
an easy to work with. The configuration is written in JSON and only specifies
environment variables. It's then embedded in the executable using file-embed.
The only thing I miss is a ToJSON instance for Config – we've found it
quite useful to log the active configuration when starting a service and that
log entry would become a bit nicer if the message was JSON rather than the
(somewhat difficult to read) string that Config's Show instance produces.
Logging
There are two requirements we have when it comes to logging
- All log entries tied to a request should have a correlation ID.
- Log requests and responses
I've written about correlation ID before, Using a configuration in Scotty.
Logging requests and responses is an area where I'm not very happy with scotty.
It feels natural to solve it using middleware (i.e. using middleware) but the
representation, especially of responses, is a bit complicated so for the time
being I've skipped logging the body of both. I'd be most interested to hear of
libraries that could make that easier.
Data storage and picking up new events
The data stream processing depends heavily on being able to pick up when new
events are written to the database. Especially when there are more than one
instance running (we usually have at least two instance running in the
production environment). To get that working I've used postgresql-simple's
support for LISTEN and NOTIFY via the function getNotification.
When I wrote about this earlier, Conduit and PostgreSQL I got some really good feedback that made my solution more robust.
Delayed actions
Some things in Haskell feel almost like cheating. The light-weight threading
makes me confident that a forkIO followed by a threadDelay (or in my case,
the ones from unliftio) will suffice.
Footnotes:
It has happened in the past that we've changed SMS service after finding that they weren't living up to our expectations.
A while ago I was experimenting with other streaming libraries, but I gave up on getting re-combination to work – Zipping streams
The ReaderT design pattern or tagless final?
The other week I read V. Kevroletin's Introduction to Tagless Final and realised that a couple of my projects, both at work and at home, would benefit from a refactoring to that approach. All in all I was happy with the changes I made, even though I haven't made use of all the way. In particular there I could further improve the tests in a few places by adding more typeclasses. For now it's good enough and I've clearly gotten some value out of it.
I found mr. Kevroletin's article to be a good introduction so I've been passing it on when people on the Functional programming slack bring up questions about how to organize their code as applications grow. In particular if they mention that they're using monad transformers. I did exactly that just the other day @solomon wrote
so i've created a rats nest of IO where almost all the functions in my program are in
ReaderT Env IO ()and I'm not sure how to purify everything and move the IO to the edge of the program
I proposed tagless final and passed the URL on, and then I got a pointer to the article The ReaderT Design Patter which I hadn't seen before.
The two approches are similar, at least to me, and I can't really judge if one's
better than the other. Just to get a feel for it I thought I'd try to rewrite
the example in the ReaderT article in a tagless final style.
A slightly changed example of ReaderT design pattern
I decided to make a few changes to the example in the article:
- I removed the
modifyfunction, instead the code uses the typeclass functionmodifyBalancedirectly. - I separated the instances needed for the tests spatially in the code just to make it easier to see what's "production" code and what's test code.
- I combined the
mainfunctions from the various examples to that both an example (main0) and the test (main1) are run. - I switched from
Control.Concurrent.Async.Lifted.Safe(frommonad-control) toUnliftIO.Async(fromunliftio)
After that the code looks like this
{-# LANGUAGE FlexibleContexts #-} {-# LANGUAGE FlexibleInstances #-} import Control.Concurrent.STM import Control.Monad.Reader import qualified Control.Monad.State.Strict as State import Say import Test.Hspec import UnliftIO.Async data Env = Env { envLog :: !(String -> IO ()) , envBalance :: !(TVar Int) } class HasLog a where getLog :: a -> (String -> IO ()) instance HasLog Env where getLog = envLog class HasBalance a where getBalance :: a -> TVar Int instance HasBalance Env where getBalance = envBalance class Monad m => MonadBalance m where modifyBalance :: (Int -> Int) -> m () instance (HasBalance env, MonadIO m) => MonadBalance (ReaderT env m) where modifyBalance f = do env <- ask liftIO $ atomically $ modifyTVar' (getBalance env) f logSomething :: (MonadReader env m, HasLog env, MonadIO m) => String -> m () logSomething msg = do env <- ask liftIO $ getLog env msg main0 :: IO () main0 = do ref <- newTVarIO 4 let env = Env { envLog = sayString , envBalance = ref } runReaderT (concurrently_ (modifyBalance (+ 1)) (logSomething "Increasing account balance")) env balance <- readTVarIO ref sayString $ "Final balance: " ++ show balance instance HasLog (String -> IO ()) where getLog = id instance HasBalance (TVar Int) where getBalance = id instance Monad m => MonadBalance (State.StateT Int m) where modifyBalance = State.modify main1 :: IO () main1 = hspec $ do describe "modify" $ do it "works, IO" $ do var <- newTVarIO (1 :: Int) runReaderT (modifyBalance (+ 2)) var res <- readTVarIO var res `shouldBe` 3 it "works, pure" $ do let res = State.execState (modifyBalance (+ 2)) (1 :: Int) res `shouldBe` 3 describe "logSomething" $ it "works" $ do var <- newTVarIO "" let logFunc msg = atomically $ modifyTVar var (++ msg) msg1 = "Hello " msg2 = "World\n" runReaderT (logSomething msg1 >> logSomething msg2) logFunc res <- readTVarIO var res `shouldBe` (msg1 ++ msg2) main :: IO () main = main0 >> main1
I think the distinguising features are
- The application environmant,
Envwill contain configuraiton values (not in this example), state,envBalance, and functions we might want to vary,envLog - There is no explicit type representing the execution context
- Typeclasses are used to abstract over application environment,
HasLogandHasBalance - Typeclasses are used to abstract over operations,
MonadBalance - Typeclasses are implemented for both the application environment,
HasLogandHasBalance, and the execution context,MonadBalance
In the end this makes for code with very loose couplings; there's not really any
single concrete type that implements all the constraints to work in the "real"
main function (main0). I could of course introduce a type synonym for it
type App = ReaderT Env IO
but it brings no value – it wouldn't be used explicitly anywhere.
A tagless final version
In order to compare the ReaderT design pattern to tagless final (as I
understand it) I made an attempt to translate the code above. The code below is
the result.1
{-# LANGUAGE FlexibleContexts #-} {-# LANGUAGE FlexibleInstances #-} {-# LANGUAGE GeneralizedNewtypeDeriving #-} {-# LANGUAGE MultiParamTypeClasses #-} {-# LANGUAGE TypeFamilies #-} import Control.Concurrent.STM import qualified Control.Monad.Identity as Id import Control.Monad.Reader import qualified Control.Monad.State.Strict as State import Say import Test.Hspec import UnliftIO (MonadUnliftIO) import UnliftIO.Async newtype Env = Env {envBalance :: TVar Int} newtype AppM a = AppM {unAppM :: ReaderT Env IO a} deriving (Functor, Applicative, Monad, MonadIO, MonadReader Env, MonadUnliftIO) runAppM :: Env -> AppM a -> IO a runAppM env app = runReaderT (unAppM app) env class Monad m => ModifyM m where mModify :: (Int -> Int) -> m () class Monad m => LogSomethingM m where mLogSomething :: String -> m() instance ModifyM AppM where mModify f = do ref <- asks envBalance liftIO $ atomically $ modifyTVar' ref f instance LogSomethingM AppM where mLogSomething = liftIO . sayString main0 :: IO () main0 = do ref <- newTVarIO 4 let env = Env ref runAppM env (concurrently_ (mModify (+ 1)) (mLogSomething "Increasing account balance")) balance <- readTVarIO ref sayString $ "Final balance: " ++ show balance newtype ModifyAppM a = ModifyAppM {unModifyAppM :: State.StateT Int Id.Identity a} deriving (Functor, Applicative, Monad, State.MonadState Int) runModifyAppM :: Int -> ModifyAppM a -> (a, Int) runModifyAppM s app = Id.runIdentity $ State.runStateT (unModifyAppM app) s instance ModifyM ModifyAppM where mModify = State.modify' newtype LogAppM a = LogAppM {unLogAppM :: ReaderT (TVar String) IO a} deriving (Functor, Applicative, Monad, MonadIO, MonadReader (TVar String)) runLogAppM :: TVar String -> LogAppM a -> IO a runLogAppM env app = runReaderT (unLogAppM app) env instance LogSomethingM LogAppM where mLogSomething msg = do var <- ask liftIO $ atomically $ modifyTVar var (++ msg) main1 :: IO () main1 = hspec $ do describe "mModify" $ do it "works, IO" $ do var <- newTVarIO 1 runAppM (Env var) (mModify (+ 2)) res <- readTVarIO var res `shouldBe` 3 it "works, pure" $ do let (_, res) = runModifyAppM 1 (mModify (+ 2)) res `shouldBe` 3 describe "mLogSomething" $ it "works" $ do var <- newTVarIO "" runLogAppM var (mLogSomething "Hello" >> mLogSomething "World!") res <- readTVarIO var res `shouldBe` "HelloWorld!" main :: IO () main = main0 >> main1
The steps for the "real" part of the program were
- Introduce an execution type,
AppM, with a convenience function for running it,runAppM - Remove the log function from the environment type,
envLoginEnv - Remove all the
HasXclasses - Create a new operations typeclass for logging,
LogSomethingM - Rename the operations typeclass for modifying the balance to match the naming
found in the tagless article a bit better,
ModifyM - Implement instances of both operations typeclasses for
AppM
For testing the steps were
- Define an execution type for each test,
ModifyAppMandLogAppM, with some convenience functions for running them,runModifyAppMandrunLogAppM - Write instances for the operations typeclasses, one for each
So I think the distinguising features are
- There's both an environment type,
Env, and an execution typeAppMthat wraps it - The environment holds only configuration values (none in this example), and
state (
envBalance) - Typeclasses are used to abstract over operations,
LogSomethingMandModifyM - Typeclasses are only implemented for the execution type
This version has slightly more coupling, the execution type specifies the environment to use, and the operations are tied directly to the execution type. However, this coupling doesn't really make a big difference – looking at the pure modify test the amount of code don't differ by much.
A short note (mostly to myself)
I did write it using monad-control first, and then I needed an instance for
MonadBaseControl IO. Deriving it automatically requires UndecidableInstances
and I didn't really dare turn that on, so I ended up writing the instance. After
some help on haskell-cafe it ended up looking like this
instance MonadBaseControl IO AppM where type StM AppM a = a liftBaseWith f = AppM (liftBaseWith $ \ run -> f (run . unAppM)) restoreM = return
Conclusion
My theoretical knowledge isn't anywhere near good enough to say anything
objectively about the difference in expressiveness of the two design patterns.
That means that my conclusion comes down to taste, do you like the readerT
patter or tagless final better?
I like the slightly looser coupling I get with the ReaderT pattern. Loose
coupling is (almost) always a desirable goal. However, I can see that tying the
typeclass instances directly to a concrete execution type results in the intent
being communicated a little more clearly. Clearly communicating intent in code
is also a desirable goal. In particular I suspect it'll result in more
actionable error messages when making changes to the code – the error will tell
me that my execution type lacks an instance of a specific typeclass, instead of
it telling me that a particular transformer stack does. On the other hand, in
the ReaderT pattern that stack is very shallow.
One possibility would be that one pattern is better suited for libraries and the other for applications. I don't think that's the case though as in both cases the library code would be written in a style that results in typeclass constraints on the caller and providing instances for those typeclasses is roughly an equal amount of work for both styles.
Footnotes:
Please do point out any mistakes I've made in this, in particular if they stem from me misunderstanding tagless final completely.
Tagless final and Scotty
For a little while I've been playing around with event sourcing in Haskell using
Conduit and Scotty. I've come far enough that the basic functionality I'm
after is there together with all those little bits that make it a piece of
software that's fit for deployment in production (configuration, logging, etc.).
There's just one thing that's been nagging me, testability.
The app is built of two main parts, a web server (Scotty) and a pipeline of
stream processing components (Conduit). The part using Scotty is utilising a
simple monad stack, ReaderT Config IO, and the Conduit part is using
Conduit In Out IO. This means that in both parts the outer edge, the part
dealing with the outside world, is running in IO directly. Something that
isn't really aiding in testing.
I started out thinking that I'd rewrite what I have using a free monad with a
bunch of interpreters. Then I remembered that I have "check out tagless final".
This post is a record of the small experiments I did to see how to use it with
Scotty to achieve (and actually improve) on the code I have in my
production-ready code.
1 - Use tagless final with Scotty
As a first simple little experiment I wrote a tiny little web server that would
print a string to stdout when receiving the request to GET /route0.
The printing to stdout is the operation I want to make abstract.
class Monad m => MonadPrinter m where mPutStrLn :: Text -> m ()
I then created an application type that is an instance of that class.
newtype AppM a = AppM { unAppM :: IO a } deriving (Functor, Applicative, Monad, MonadIO) instance MonadPrinter AppM where mPutStrLn t = liftIO $ putStrLn (unpack t)
Then I added a bit of Scotty boilerplate. It's not strictly necessary, but
does make the code a bit nicer to read.
type FooM = ScottyT Text AppM type FooActionM = ActionT Text AppM foo :: MonadIO m => Port -> ScottyT Text AppM () -> m () foo port = scottyT port unAppM
With that in place the web server itself is just a matter of tying it all together.
main :: IO () main = do foo 3000 $ do get "/route0" $ do lift $ mPutStrLn "getting /route0" json $ object ["route0" .= ("ok" :: String)] notFound $ json $ object ["error" .= ("not found" :: String)]
That was simple enough.
2 - Add configuration
In order to try out how to deal with configuration I added a class for doing some simple logging
class Monad m => MonadLogger m where mLog :: Text -> m ()
The straight forward way to deal with configuration is to create a monad stack
with ReaderT and since it's logging I want to do the configuration consists of
a single LoggerSet (from fast-logger).
newtype AppM a = AppM { unAppM :: ReaderT LoggerSet IO a } deriving (Functor, Applicative, Monad, MonadIO, MonadReader LoggerSet)
That means the class instance can be implemented like this
instance MonadLogger AppM where mLog msg = do ls <- ask liftIO $ pushLogStrLn ls $ toLogStr msg
Of course foo has to be changed too, and it becomes a little easier with a
wrapper for runReaderT and unAppM.
foo :: MonadIO m => LoggerSet -> Port -> ScottyT Text AppM () -> m () foo ls port = scottyT port (`runAppM` ls) runAppM :: AppM a -> LoggerSet -> IO a runAppM app ls = runReaderT (unAppM app) ls
With that in place the printing to stdout can be replaced by a writing to the
log.
main :: IO () main = do ls <- newStdoutLoggerSet defaultBufSize foo ls 3000 $ do get "/route0" $ do lift $ mLog "log: getting /route0" json $ object ["route0" .= ("ok" :: String)] notFound $ json $ object ["error" .= ("not found" :: String)]
Not really a big change, I'd say. Extending the configuration is clearly straight forward too.
3 - Per-request configuration
At work we use correlation IDs1 and I think that the most convenient way to
deal with it is to put the correlation ID into the configuration after
extracting it. That is, I want to modify the configuration on each request.
Luckily it turns out to be possible to do that, despite using ReaderT for
holding the configuration.
I can't be bothered with a full implementation of correlation ID for this little
experiment, but as long as I can get a new AppM by running a function on the
configuration it's just a matter of extracting the correct header from the
request. For this experiment it'll do to just modify an integer in the
configuration.
I start with defining a type for the configuration and changing AppM.
type Config = (LoggerSet, Int) newtype AppM a = AppM { unAppM :: ReaderT Config IO a } deriving (Functor, Applicative, Monad, MonadIO, MonadReader Config)
The logger instance has to be changed accordingly of course.
instance MonadLogger AppM where mLog msg = do (ls, i) <- ask liftIO $ pushLogStrLn ls $ toLogStr msg <> toLogStr (":" :: String) <> toLogStr (show i)
The get function that comes with scotty isn't going to cut it, since it has
no way of modifying the configuration, so I'll need a new one.
mGet :: ScottyError e => RoutePattern -> ActionT e AppM () -> ScottyT e AppM () mGet p a = get p $ do withCfg (\ (ls, i) -> (ls, succ i)) a
The tricky bit is in the withCfg function. It's indeed not very easy to read,
I think
withCfg = mapActionT . withAppM where mapActionT f (ActionT a) = ActionT $ (mapExceptT . mapReaderT . mapStateT) f a withAppM f a = AppM $ withReaderT f (unAppM a)
Basically it reaches into the guts of scotty's ActionT type (the details are
exposed in Web.Scotty.Internal.Types, thanks for not hiding it completely),
and modifies the ReaderT Config I've supplied.
The new server has two routes, the original one and a new one at GET /route1.
main :: IO () main = do putStrLn "Starting" ls <- newStdoutLoggerSet defaultBufSize foo (ls, 0) 3000 $ do get "/route0" $ do lift $ mLog "log: getting /route0" json $ object ["route0" .= ("ok" :: String)] mGet "/route1" $ do lift $ mLog "log: getting /route1" json $ object ["route1" .= ("bar" :: String)] notFound $ json $ object ["error" .= ("not found" :: String)]
It's now easy to verify that the original route, GET /route0, logs a string
containing the integer '0', while the new route, GET /route1, logs a string
containing the integer '1'.
Footnotes:
If you don't know what it is you'll find multiple sources by searching for "http correlation-id". A consistent approach to track correlation IDs through microservices is as good a place to start as any.